क्लासेस और स्ट्रक्ट्स के बीच के मूल अंतर अनलॉक करें। जानें कि उच्च-प्रदर्शन और स्वच्छ कोड के लिए C#, Swift, C++, और अन्य भाषाओं में किसे कब उपयोग करना चाहिए।
January 29, 2026 (3mo ago)
Classes vs Structs: एक डेवलपर की परफ़ॉर्मेंस गाइड
क्लासेस और स्ट्रक्ट्स के बीच के मूल अंतर अनलॉक करें। जानें कि उच्च-प्रदर्शन और स्वच्छ कोड के लिए C#, Swift, C++, और अन्य भाषाओं में किसे कब उपयोग करना चाहिए।
← Back to blog
Classes vs Structs: एक डेवलपर की परफ़ॉर्मेंस गाइड
सारांश: क्लासेस और स्ट्रक्ट्स के बीच के मूल अंतर अनलॉक करें। जानें कि उच्च-प्रदर्शन और स्वच्छ कोड के लिए C#, Swift, C++, और अन्य भाषाओं में किसे कब उपयोग करना चाहिए।
परिचय
क्लासेस और स्ट्रक्ट्स के बीच मूल अंतर सरल पर निर्णायक है: क्लासेस रेफरेंस टाइप हैं और स्ट्रक्ट्स वैल्यू टाइप। यह फर्क मेमोरी लेआउट, कॉपी व्यवहार, और रनटाइम परफ़ॉर्मेंस को संचालित करता है—खासकर C#, C++, और Swift जैसी भाषाओं में। कब किसे चुनना है, यह समझना प्रत्याशित कोड और उच्च-प्रदर्शन सिस्टम्स के लिए आवश्यक है।
मौलिक अंतर को समझना
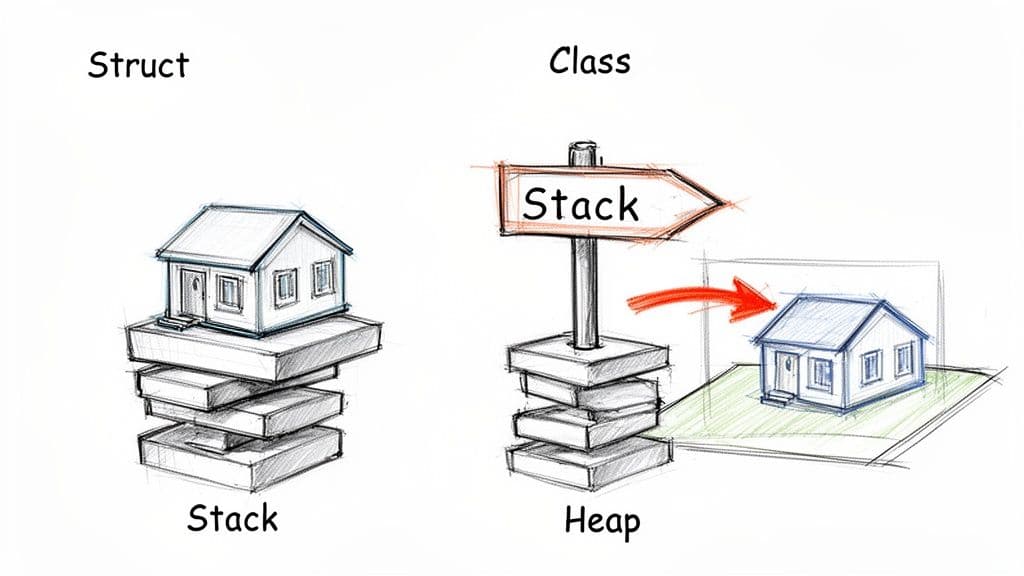
जब आप किसी क्लास का उदाहरण बनाते हैं, तो आपके पास जो वेरिएबल होता है वह एक रेफरेंस होता है जो हीप पर ऑब्जेक्ट की ओर इशारा करता है। उस वेरिएबल की कॉपी करने पर केवल रेफरेंस कॉपी होता है; कई रेफरेंस एक ही ऑब्जेक्ट की ओर इशारा कर सकते हैं, इसलिए एक रेफरेंस के माध्यम से किए गए परिवर्तन दूसरों से दिखाई देते हैं। यह रेफरेंस सिमेंटिक्स उस कारणों में से एक है कि क्लासेस उन एंटिटीज़ के लिए उपयोग की जाती हैं जिनकी पहचान होती है।1
एक स्ट्रक्ट खुद डेटा का प्रतिनिधित्व करता है। स्ट्रक्ट बनाने से मानों का एक ठोस बंडल बनता है—अक्सर स्टैक पर या ऐरे में इनलाइन संग्रहीत—इसलिए स्ट्रक्ट की कॉपी एक स्वतंत्र डुप्लिकेट देती है। कॉपी को संशोधित करने से मूल प्रभावित नहीं होता, जो सरल, इम्यूटेबल मानों के लिए स्ट्रक्ट्स को उत्कृष्ट बनाता है।1
एन्कैप्सुलेशन और ऑब्जेक्ट डिज़ाइन पर अधिक के लिए, हमारी गाइड देखें: https://cleancodeguy.com/blog/object-oriented-encapsulation.
त्वरित तुलना: रेफरेंस बनाम वैल्यू टाइप
| विशेषता | क्लास (रेफरेंस टाइप) | स्ट्रक्ट (वैल्यू टाइप) |
|---|---|---|
| मेमोरी स्थान | हीप; ऑब्जेक्ट पॉइंटर द्वारा संदर्भित। | स्टैक या इनलाइन; वेरिएबल ही डेटा होता है। |
| असाइनमेंट | ऑब्जेक्ट की बजाय रेफरेंस की कॉपी करता है। | पूरा मान कॉपी करता है। |
| जीवनकाल | गार्बेज कलेक्शन द्वारा प्रबंधित (या कुछ भाषाओं में मैनुअल डिलीशन)। | स्कोप से बाहर होने पर या इनलाइन स्टोर होने पर डीएलोकेट हो जाता है। |
| पहचान बनाम मान | पहचान होती है; एक ही इंस्टेंस पर कई रेफरेंस हो सकते हैं। | मान का प्रतिनिधित्व करता है; समानता अक्सर डेटा पर आधारित। |
जब आपको साझा पहचान की जरूरत हो तो क्लास का उपयोग करें। जब आपको एक सरल, स्व-निहित मान चाहिए जिसे बिना साइड-इफेक्ट के कॉपी किया जा सके तो स्ट्रक्ट का उपयोग करें।
यह आधार गहरी परफ़ॉर्मेंस ट्रेड-ऑफ—हीप बनाम स्टैक अलोकेशन, कैश लोकैलिटी, और गार्बेज कलेक्शन प्रेशर—को सूचित करता है, जिन्हें हम नीचे खोजते हैं।
कैसे मेमोरी अलोकेशन गति को निर्धारित करता है
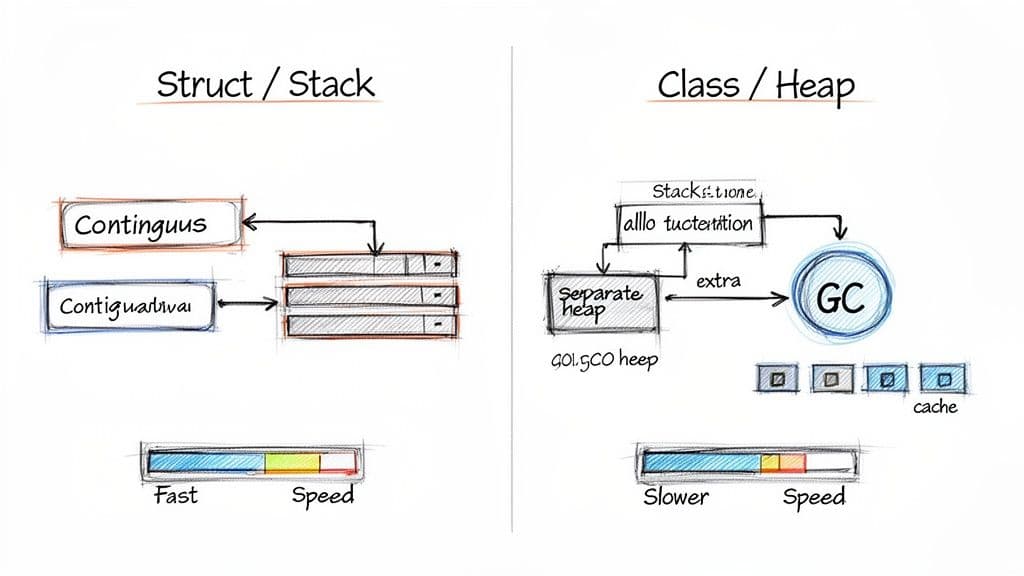
मेमोरी लेआउट CPU दक्षता, थ्रूपुट, और लेटेंसी को प्रभावित करता है। एक क्लास एक्सेस आमतौर पर एक इंडाइरेक्शन शामिल करता है: स्टैक पर एक पॉइंटर हीप पर डेटा को संदर्भित करता है। वह अतिरिक्त लुकअप लागत जोड़ता है और कैश व्यवहार को प्रभावित कर सकता है। स्ट्रक्ट्स, जहां वेरिएबल मौजूद है वहां सीधे संग्रहीत होते हैं, अक्सर उस इंडाइरेक्शन से बचते हैं और बेहतर कैश लोकैलिटी के साथ अधिक किचन मेमोरी लेआउट सक्षम करते हैं।1
गार्बेज कलेक्शन की लागत
हीप पर ऑब्जेक्ट गार्बेज कलेक्शन के अधीन होते हैं। GC साइकिल्स निष्पादन को रोक सकती हैं, जिससे रियल-टाइम या हाई-थ्रूपुट सिस्टम्स में लेटेंसी बढ़ती है। छोटे, अल्पजीवी क्लास ऑब्जेक्ट्स का बार-बार अलोकेशन GC प्रेशर और CPU ओवरहेड बढ़ाता है। कई छोटे, अल्पजीवी ऑब्जेक्ट्स के लिए वैल्यू टाइप्स का उपयोग हीप चर्न और GC काम को कम करता है।3
हीप अलोकेशन संभावित GC ओवरहेड जोड़ता है। जब स्ट्रक्ट वैल्यू-आधारित और अनबॉक्स्ड रहते हैं तो वे उस ओवरहेड से बचते हैं।
यह विशेष रूप से पैमाना और प्रतिक्रियाशीलता के लिए डिज़ाइन किए गए सिस्टम्स में महत्वपूर्ण है—अलोकेशन्स को कम करना सीधे GC गतिविधि को कम करता है और रनटाइम परफ़ॉर्मेंस को सुगम कर सकता है।
कैश लोकैलिटी और थ्रूपुट
आधुनिक CPUs कैश पर निर्भर करते हैं। अनुक्रमिक लेआउट—जैसे स्ट्रक्ट्स की ऐरे—कैश हिट्स और थ्रूपुट में सुधार करते हैं। प्रत्येक क्लास इंस्टेंस के लिए अलग-थलग हीप अलोकेशन्स डेटा को मेमोरी में बिखेर देते हैं, जिससे कैश मिस बढ़ते हैं और प्रोसेसिंग धीमी होती है। टाइट लूप्स और डेटा-प्रोसेसिंग पाइपलाइनों के लिए, contiguous वैल्यू लेआउट एक बड़ा लाभ है।5
बॉक्सिंग का जाल
बॉक्सिंग तब होती है जब एक वैल्यू टाइप को रेफरेंस टाइप में परिवर्तित किया जाता है (उदाहरण के लिए, जब उसे ऑब्जेक्ट्स की अपेक्षा रखने वाले कलेक्शन में रखा जाता है)। बॉक्सिंग एक हीप ऑब्जेक्ट अलोकेट करती है और मान को उसमें कॉपी कर देती है, जिससे स्ट्रक्ट के परफ़ॉर्मेंस लाभ रद्द हो जाते हैं और GC लोड बढ़ता है। बॉक्सिंग से बचना वैल्यू-टाइप का कुशल उपयोग करने का एक मूल सिद्धांत है।4
भाषाएँ कैसे अलग हैं: C#, C++, और Swift
विभिन्न भाषाएँ विभिन्न कन्वेंशन्स और क्षमताओं को लागू करती हैं। भाषा-विशिष्ट नियम जानने से एक भाषा के नियमों को अंधाधुंध दूसरी भाषा पर लागू करने से बचा जा सकता है।
C#: स्पष्ट रेफरेंस बनाम वैल्यू मॉडल
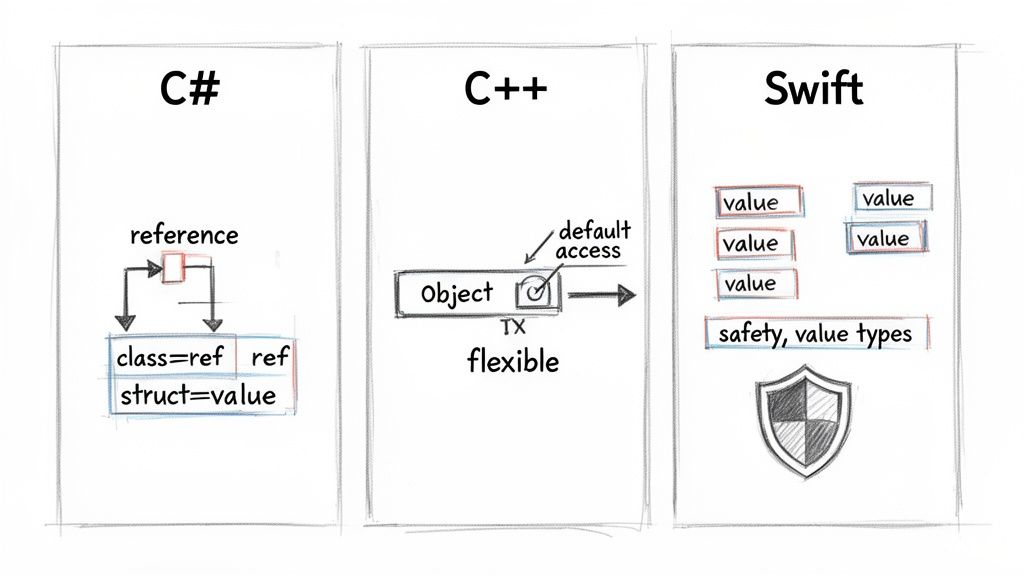
C# में, class = रेफरेंस टाइप और struct = वैल्यू टाइप। पहचान वाले एंटिटीज (उदाहरण के लिए, Customer या DatabaseConnection) के लिए क्लासेस का उपयोग करें और छोटे, इम्यूटेबल मानों (उदाहरण के लिए, Point, Color) के लिए स्ट्रक्ट्स का उपयोग करें। स्ट्रक्ट्स को छोटा और इम्यूटेबल रखना सूक्ष्म बग्स और कॉपीओवरहेड से बचाता है।1
सामान्य गलतियों में बड़े या म्यूटेबल स्ट्रक्ट्स बनाना शामिल है; दोनों ही चौंकाने वाले बग्स या परफ़ॉर्मेंस रिग्रेशन का कारण बन सकते हैं। C# में ऑप्टिमाइज़ करते समय इम्यूटेबल, छोटे-स्ट्रक्ट दिशा-निर्देश का पालन करें।
C++: भाषा-प्रतिबंध के बजाय कन्वेंशन
C++ में, struct और class के बीच केवल सिन्टैक्टिक अंतर डिफ़ॉल्ट एक्सेसिबिलिटी है। दोनों स्टैक या हीप पर अलोकेट किए जा सकते हैं, दोनों के पास मेथड्स हो सकते हैं, और इनहेरिटेंस का समर्थन करते हैं। कन्वेंशन यह है कि सरल डेटा एग्रीगेट्स के लिए struct और एनकैप्सुलेटेड ऑब्जेक्ट्स और RAII रिसोर्स मैनेजमेंट के लिए class का उपयोग करें।
यह लचीलापन मतलब है कि C++ डेवलपर्स को वैल्यू/रेफरेंस अंतर पर भाषा-प्रेरित नियमों के बजाय कन्वेंशन्स और डिज़ाइन विकल्पों पर भरोसा करना होगा। पॉलीमॉर्फ़िज़्म और इनहेरिटेंस पैटर्न्स पर मार्गदर्शन के लिए, हमारी C++ डिज़ाइन नोट्स देखें: https://cleancodeguy.com/blog/polymorphism-vs-inheritance.
Swift: डिफ़ॉल्ट रूप से वैल्यू-ओरिएंटेड
Swift अधिकांश कस्टम प्रकारों के लिए स्ट्रक्ट्स को प्राथमिकता देने के लिए प्रोत्साहित करता है। Swift में स्ट्रक्ट्स मेथड्स, एक्सटेंशन्स, और प्रोटोकॉल कन्फॉर्मेंस का समर्थन करते हैं, जिससे वे शक्तिशाली पर सुरक्षित डिफ़ॉल्ट बनते हैं। केवल तभी क्लास चुनें जब रेफरेंस सिमेंटिक्स, पहचान, या Objective-C इंटरऑपरेबिलिटी आवश्यक हो।2
यह वैल्यू-फर्स्ट डिज़ाइन इम्यूटेबिलिटी और डेटा फ्लो के बारे में सोचना आसान बनाती है, विशेष रूप से समकक्ष (concurrent) कोड में।
अधिकतम दक्षता के लिए कब स्ट्रक्ट चुनें
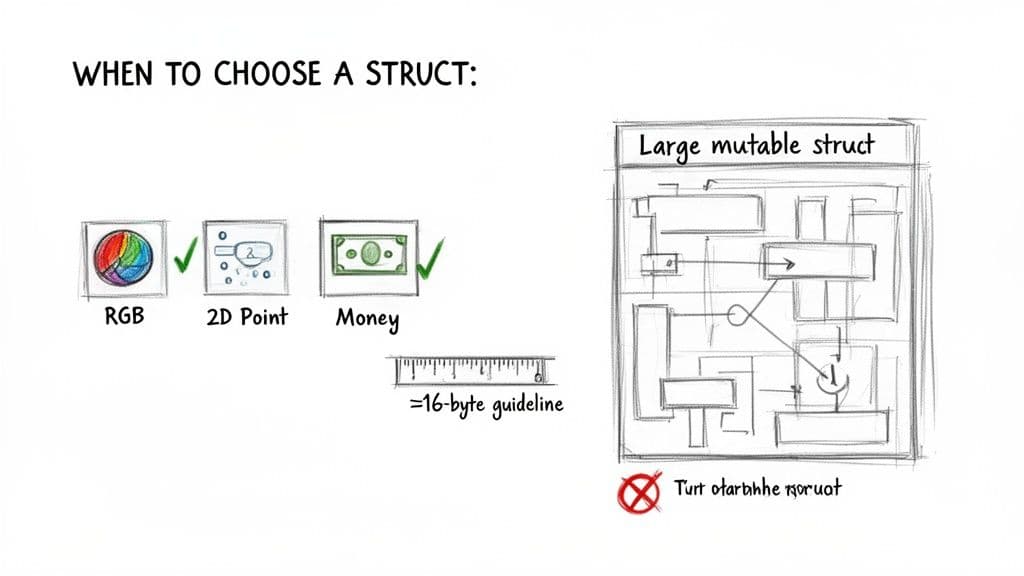
स्ट्रक्ट्स उन छोटे, इम्यूटेबल डेटा बंडलों के लिए आदर्श हैं जिनकी पहचान पूरी तरह उनके मानों द्वारा परिभाषित होती है। सामान्य उदाहरण:
- ज्योमेट्रिक डेटा: Point2D या RGBColor
- वित्तीय मान: Money (amount + currency)
- उच्च-थ्रूपुट पाइपलाइनों में प्रयुक्त छोटे DTOs
एक व्यावहारिक आकार मार्गदर्शक “16–32 बाइट” नियम है: यदि किसी स्ट्रक्ट के फील्ड लगभग उस सीमा में फिट होते हैं, तो कॉपी करने की लागत मामूली होती है और अक्सर हीप अलोकेशन से सस्ती होती है। यदि स्ट्रक्ट बड़ा हो जाता है या उसे म्यूटेबल होना चाहिए, तो क्लास बेहतर विकल्प है।5
इम्यूटेबिलिटी और आकार नियम
- इम्यूटेबल स्ट्रक्ट्स को प्राथमिकता दें: मान एक बार बनाए जाने चाहिए और स्थिति बदलने पर बदले जाने के बजाय नए उदाहरण लौटाना चाहिए।
- स्ट्रक्ट्स को छोटा रखें: बड़े स्ट्रक्ट्स की बार-बार कॉपी करना संदर्भ पास करने की तुलना में अधिक महंगा हो सकता है।
ये नियम साइलेंट बग्स (म्यूटेबल कॉपियों से) और परफ़ॉर्मेंस जाल (अत्यधिक कॉपी या बॉक्सिंग से) से बचने में मदद करते हैं।
सामान्य जाल और रिफैक्टोरिंग
दो सामान्य समस्याएँ म्यूटेबल स्ट्रक्ट्स और अत्यधिक बॉक्सिंग हैं।
म्यूटेबल स्ट्रक्ट्स आश्चर्यजनक व्यवहार की ओर ले जाते हैं क्योंकि संशोधन केवल एक कॉपी को प्रभावित करते हैं। म्यूटेबल स्ट्रक्ट्स को इम्यूटेबल में रिफैक्टर करें जो स्थिति परिवर्तन के लिए नए इंस्टेंस लौटाते हैं।
बॉक्सिंग कई APIs और कलेक्शन्स में अनायास होती है; बॉक्सिंग हॉटस्पॉट्स की पहचान करें और उन्हें हटाएँ ताकि स्ट्रक्ट परफ़ॉर्मेंस लाभ बरक़रार रहें।
उदाहरण: C# में म्यूटेबल पॉइंट को इम्यूटेबल स्ट्रक्ट में रिफैक्टर करें
// PITFALL: Mutable struct public struct MutablePoint { public int X { get; set; } public int Y { get; set; }
public void Move(int dx, int dy)
{
X += dx;
Y += dy;
}
}
// REFACTOR: Immutable struct public readonly struct ImmutablePoint { public int X { get; } public int Y { get; }
public ImmutablePoint(int x, int y)
{
X = x;
Y = y;
}
public ImmutablePoint MovedBy(int dx, int dy)
{
return new ImmutablePoint(X + dx, Y + dy);
}
}
यह रिफैक्टर इरादा स्पष्ट बनाती है और आकस्मिक स्थिति भ्रष्टाचार को समाप्त करती है। स्वच्छ-कोड अभ्यासों के बारे में और जानने के लिए, हमारी सिद्धांत गाइड देखें: https://cleancodeguy.com/blog/clean-coding-principles.
अक्सर पूछे जाने वाले प्रश्न (संक्षिप्त Q&A)
Q1: मुझे कब क्लास की तुलना में स्ट्रक्ट पसंद करना चाहिए?
A: उस समय स्ट्रक्ट पसंद करें जब प्रकार छोटा, इम्यूटेबल हो और पहचान की बजाय मान का प्रतिनिधित्व करता हो। पॉइंट्स, रंग, या छोटे DTOs जैसे सरल डेटा के लिए स्ट्रक्ट्स बेहतर होते हैं।
Q2: मुझे किन परफ़ॉर्मेंस जालों पर नज़र रखनी चाहिए?
A: म्यूटेबल स्ट्रक्ट्स, बड़े स्ट्रक्ट्स (कॉपी लागत), और हीप ऑब्जेक्ट्स में बॉक्सिंग से बचें—ये सभी वैल्यू टाइप्स के लाभों को शून्य कर सकते हैं और परफ़ॉर्मेंस को हानि पहुँचा सकते हैं।
Q3: भाषा-भिन्नताएँ मेरे चुनाव को कैसे प्रभावित करती हैं?
A: भाषा के आदर्शों का पालन करें: C# वैल्यू बनाम रेफरेंस टाइप को लागू करता है; C++ कन्वेंशन का उपयोग करता है; Swift डिफ़ॉल्ट रूप से वैल्यू टाइप्स को प्राथमिकता देता है। क्रॉस-भाषा पैटर्न लागू करने से पहले प्लेटफ़ॉर्म नियम सीखें।12
Clean Code Guy पर, हम टीमों को इन सिद्धांतों को वास्तविक कोडबेस पर लागू करने में मदद करते हैं। हमारे Codebase Cleanups और AI-Ready Refactors सॉफ़्टवेयर को तेज़, सुरक्षित, और बनाए रखने में आसान बनाते हैं। अधिक जानने के लिए देखें: https://cleancode.com.
1.
Microsoft Docs, “Choosing between classes and structs,” https://learn.microsoft.com/en-us/dotnet/standard/choosing-between-class-and-struct
2.
Apple Developer Documentation, “Structures and Classes,” https://docs.swift.org/swift-book/LanguageGuide/ClassesAndStructures.html
3.
Microsoft Docs, “Garbage Collection,” https://learn.microsoft.com/en-us/dotnet/standard/garbage-collection/
4.
Microsoft Docs, “Boxing and Unboxing,” https://learn.microsoft.com/en-us/dotnet/standard/boxing-unboxing
5.
NDepend Blog, “Class vs Struct in C#: Making Informed Choices,” https://blog.ndepend.com/class-vs-struct-in-c-making-informed-choices/
6.
Performance comparison and benchmarks, Sergey Teplyakov, https://sergeyteplyakov.github.io/Blog/benchmarking/2023/11/02/Performance_Comparison_For_Classes_vs_Structs.html
🙋🏻♂️
AI कोड लिखता है।आप इसे टिकाऊ बनाते हैं।
AI त्वरण के युग में, क्लीन कोड केवल एक अच्छी प्रथा नहीं है — यह उन प्रणालियों के बीच का अंतर है जो स्केल होती हैं और कोडबेस जो अपने वजन के तहत ढह जाते हैं।