Dowiedz się, jak opanowanie konwencji nazewnictwa w programowaniu prowadzi do czystszego, bardziej skalowalnego kodu. Poznaj praktyczne zasady, automatyzację i strategie wdrażania.
February 4, 2026 (2mo ago)
Przewodnik po konwencjach nazewnictwa w programowaniu dla czystego kodu
Dowiedz się, jak opanowanie konwencji nazewnictwa w programowaniu prowadzi do czystszego, bardziej skalowalnego kodu. Poznaj praktyczne zasady, automatyzację i strategie wdrażania.
← Back to blog
Konwencje nazewnictwa dla czystego, skalowalnego kodu
Dowiedz się, jak opanowanie konwencji nazewnictwa w programowaniu prowadzi do czystszego, bardziej skalowalnego kodu. Poznaj praktyczne zasady, automatyzację i strategie wdrażania.
Wprowadzenie
Konwencje nazewnictwa to coś więcej niż wybór stylu — to wspólny język, który sprawia, że kod jest czytelny, łatwy w utrzymaniu i bezpieczniejszy przy zmianach. Dobre nazwy zmniejszają obciążenie poznawcze, przyspieszają wdrażanie nowych osób i poprawiają automatyzację, od linterów po asystentów AI. Ten przewodnik przedstawia praktyczne zasady dla TypeScript, React i Node oraz strategie egzekwowania i wdrażania, by konwencje się utrwaliły.
Dlaczego konwencje nazewnictwa są pierwszą linią obrony bazy kodu
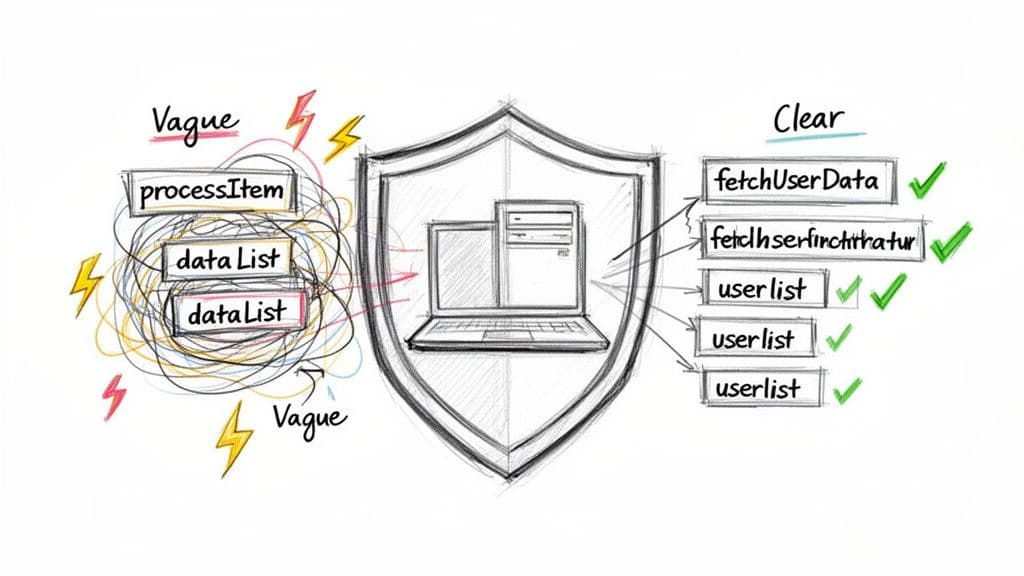
Nazewnictwo nie dotyczy estetyki; chodzi o jasną komunikację. Każda zmienna, funkcja i komponent jest częścią opowieści Twojej aplikacji. Niejasne lub niespójne nazwy zmuszają czytelnika do zatrzymania się i poszukiwania kontekstu, zamieniając drobne poprawki w czasochłonne zadania.
Jedna niejasna nazwa funkcji może kosztować minuty lub godziny na debugowanie. Gdy zdarza się to w całym zespole, spada wydajność, a incydenty stają się bardziej prawdopodobne. Baza kodu z jasnym, konsekwentnym nazewnictwem staje się w praktyce „samodokumentująca się”, zmniejszając potrzebę długich komentarzy i ułatwiając poruszanie się po systemie.
Realne koszty złego nazewnictwa
Weźmy na przykład backend Node.js z funkcją o nazwie processItem() i argumentem nazwanym dataList. Co ona właściwie robi? Aby to ustalić, możesz być zmuszony przeczytać implementację, prześledzić wywołania lub uruchomić debugger. Te objazdy się kumulują i mogą prowadzić do realnych błędów, gdy założenia nie są jasne.
Audyt przeprowadzony w projektach we wczesnej fazie wykazał powszechną niespójność w nazewnictwie i mierzalne spowolnienia przy wdrażaniu i debugowaniu, co podkreśla, jak nazewnictwo wpływa na prędkość i niezawodność zespołu.1
Statistics Canada również podkreśla, jak spójne standardy zmniejszają błędy integracji w projektach rządowych, pokazując, że nazewnictwo i standaryzacja mają znaczenie na dużą skalę.2
Konwencje nazewnictwa a skalowalność zespołu
Problem narasta wraz ze wzrostem zespołów. Niespójne nazewnictwo utrudnia nowym pracownikom zrozumienie kodu i spowalnia współpracę. Przyjęcie wspólnych konwencji wcześnie zapobiega długowi dziedziczonym i zmniejsza tarcia podczas skalowania.
Najpopularniejsze style nazewnictwa w skrócie
Ten szybki skrót pokazuje popularne style zapisu i gdzie zwykle się je stosuje:
| Case Style | Example | Primary Use Case |
|---|---|---|
| camelCase | let userName = "Alex"; | Variables and functions (JavaScript/TypeScript) |
| PascalCase | class UserProfile {} | Classes, interfaces, types, React components |
| snake_case | const API_KEY = "..."; | Constants or languages like Python |
| kebab-case | user-profile.css | CSS class names, file names, and URLs |
Zrozumienie, kiedy używać każdego stylu, buduje przewidywalny słownik w całym projekcie.
Przygotowanie kodu do współpracy z AI
Narzędzia AI, takie jak GitHub Copilot i Cursor, działają najlepiej przy spójnym kodzie. Uczą się wzorców z Twojej bazy kodu i odzwierciedlają je w sugestiach.
- Przewidywalne sugestie AI: wartości boolean poprzedzone
islubhasprowadzą do czytelniejszej logiki warunkowej. - Dokładne generowanie funkcji: funkcje pobierające dane konsekwentnie nazywane
fetchSomethingpomagają AI tworzyć poprawny kod asynchroniczny. - Sprytniejsze refaktoryzacje: spójne nazwy pomagają narzędziom wykrywać powiązania i wprowadzać bezpieczniejsze zmiany.
Uczynienie konwencji nazewnictwa jawnych poprawia czytelność dla ludzi i sprawia, że asystenci AI stają się bardziej niezawodnymi współpracownikami.
Praktyczne zasady nazewnictwa dla TypeScript, React i Node
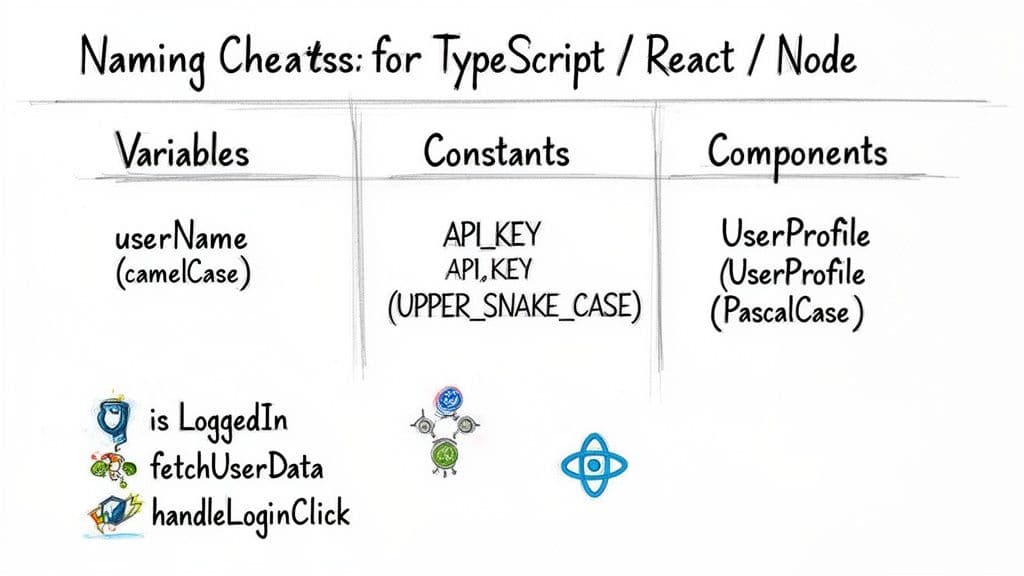
Te zasady są przetestowane w boju dla nowoczesnych stosów webowych i zmniejszają obciążenie poznawcze w zespole.
Podstawowe konwencje JavaScript i TypeScript
-
Zmienne i funkcje: używaj camelCase
- Dobrze:
let userProfile = {}; - Dobrze:
function calculateTotalPrice() {} - Źle:
let UserProfile = {};(wygląda jak klasa)
- Dobrze:
-
Klasy, interfejsy, typy: używaj PascalCase
- Dobrze:
class AuthenticationService {} - Dobrze:
interface User { id: string }
- Dobrze:
-
Prawdziwe stałe: używaj UPPER_SNAKE_CASE
- Dobrze:
const API_BASE_URL = '...' - Dobrze:
const MAX_LOGIN_ATTEMPTS = 5;
- Dobrze:
Opanowanie tych podstaw sprawia, że identyfikatory są natychmiast rozpoznawalne.
Nazewnictwo semantyczne dla jasności
Używaj słów i prefiksów sygnalizujących intencję. Jasne rozróżnienia między zmiennymi a funkcjami zmniejszają ilość błędów i błędnych interpretacji. Badania i audyty pokazują, że zespoły, które przyjmują jawne nazwy, redukują liczbę błędów i poprawiają utrzymywalność.3
Zasady specyficzne dla React
-
Komponenty i nazwy plików: używaj PascalCase
function UserProfile() { ... }→ plikUserProfile.tsx
-
Handlery zdarzeń: poprzedzaj
handlefunction handleLoginClick() { ... }
-
Pary z useState: stosuj
[thing, setThing]const [isLoading, setIsLoading] = useState(false);
Nazewnictwo zorientowane na akcję i opisowe
- Booleany: poprzedzaj
is,haslubcan(isModalOpen,hasUnsavedChanges) - Funkcje: nazywaj czasownikami (
fetchUserData,validateInput,saveSettings)
Przyjmij nazwy, które czytają się jak zwykłe zdania po angielsku — to sprawia, że kod jest bardziej intuicyjny i zmniejsza potrzebę komentowania.
Automatyzacja spójności w celu egzekwowania zasad nazewnictwa
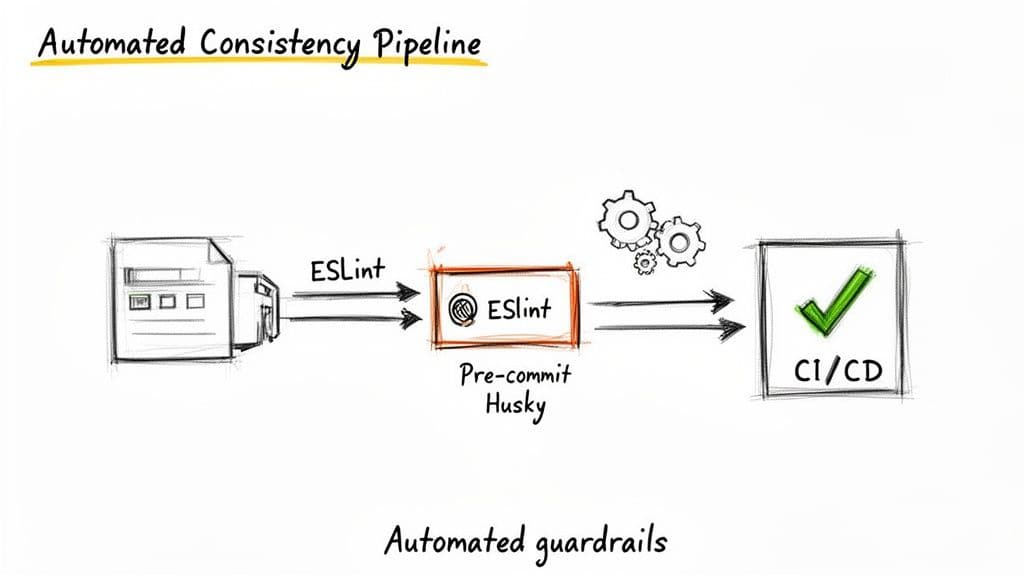
Zdefiniowanie zasad to pierwszy krok; automatyzacja sprawia, że się utrzymują. Poleganie wyłącznie na code review w kwestii spójności nazewnictwa marnuje czas recenzentów i pozostawia luki.
ESLint: Twoja pierwsza linia obrony
ESLint dostarcza informacje w czasie rzeczywistym w edytorach i może egzekwować zasady nazewnictwa za pomocą reguł niestandardowych lub wtyczek. Używaj współdzielonej konfiguracji ESLint, aby wszyscy mieli te same kontrole.
- Korekty w czasie rzeczywistym zapobiegają błędom przed ich zapisaniem.
- Dostosowane reguły egzekwują konwencje specyficzne dla zespołu (np. prefiksy dla booleanów).
- Wspólne konfiguracje kończą dyskusje o stylu i zmniejszają tarcia.
Hooki pre-commit z Husky
Husky uruchamia skrypty przy zatwierdzaniu commitów. W połączeniu z lint-staged zapobiega wprowadzeniu do repo kodu niespełniającego reguł, uruchamiając ESLint na staged plikach i odrzucając commity, które nie przejdą kontroli.
Linting w CI
Zawsze uruchamiaj linter w CI jako ostateczną bramę. CI działa jako obiektywne źródło prawdy i blokuje pull requesty, które wprowadzają naruszenia nazewnictwa lub inne błędy stylu.
To podejście trójwarstwowe — linting w edytorze, pre-commit hooki i CI — egzekwuje standardy przy minimalnym ręcznym nadzorze.
Projektowanie struktury plików i folderów
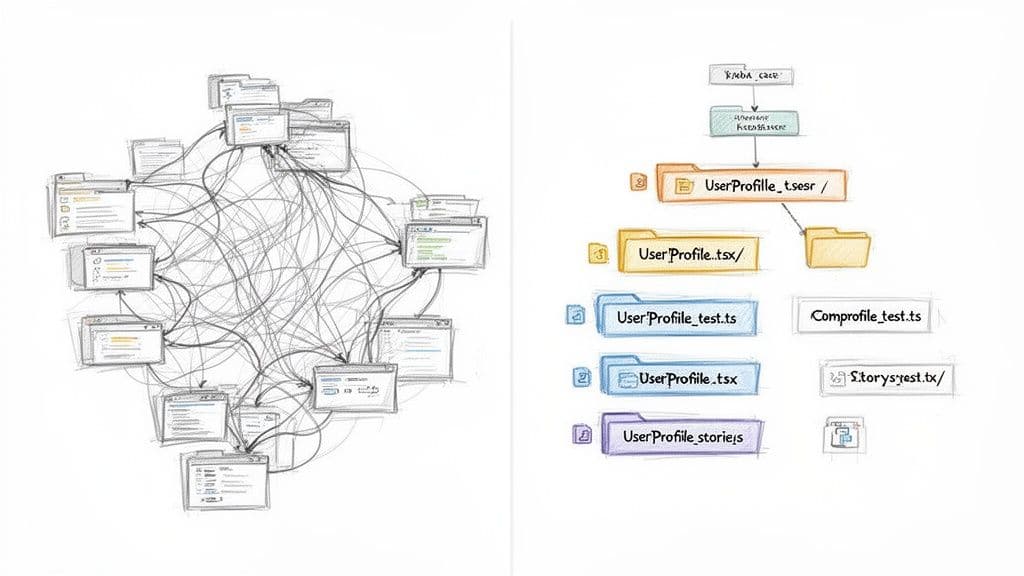
Konwencje nazewnictwa rozciągają się także na pliki i katalogi. Przewidywalna architektura pomaga nowym deweloperom szybko znaleźć kod i zmniejsza obciążenie poznawcze przy wprowadzaniu zmian.
Organizacja według funkcji, a nie według typu
Organizuj kod wokół funkcji lub domen, zamiast według typu pliku. Lokalizuj komponenty, serwisy, hooki i testy dla danej funkcji w tym samym katalogu. Na przykład umieść wszystko związane z uwierzytelnianiem w /auth.
To sprawia, że funkcje są samowystarczalne i łatwiejsze do zrozumienia, testowania lub usunięcia.
Podstawowe zasady nazewnictwa plików
- Katalogi: używaj kebab-case (
user-profile,auth-service) - Komponenty React: PascalCase (
UserProfile.tsx) - Narzędzia i serwisy: camelCase (
apiClient.ts,stringUtils.ts) - Używaj opisowych sufiksów (
.test.ts,.stories.tsx,.styles.ts)
Spójny system plików zmniejsza konflikty przy scalaniu i pomaga zespołom rozproszonym lepiej współpracować.
Jak wprowadzić nowe konwencje w istniejącej bazie kodu
Pełna, natychmiastowa refaktoryzacja jest ryzykowna. Zamiast tego przyjmij podejście przyrostowe: zostawaj zawsze kod trochę czyściejszy, niż go zastałeś.
Zacznij od rozmowy
Zdobądź poparcie zespołu, wyjaśniając mierzalne korzyści: szybsze wdrożenie nowych osób, mniej błędów i lepsza produktywność deweloperów. Przeprowadź pilotaż na jednym module, aby pokazać zyski i zbudować impet.
Udokumentuj zasady
Umieść konwencje w CONTRIBUTING.md lub w README projektu. Użyj jasnych przykładów pokazujących, co jest dobrą, a co złą praktyką. Krótko wyjaśnij racjonalność, aby zasady lepiej się utrwaliły.
Pozwól linterowi wykonać ciężką pracę
Skonfiguruj narzędzia tak, by egzekwowały zasady tylko dla nowego lub zmienionego kodu: użyj lint-staged, Husky i kontroli CI ograniczonych do zmian w PR. Unikniesz w ten sposób blokowania pracy nad dużymi plikami dziedziczonymi, a jednocześnie zapewnisz, że wszystkie nowe zmiany będą zgodne ze standardem.
Mierz sukces
Śledź sygnały takie jak:
- Mniej uwag w PR dotyczących nazewnictwa
- Szybsze cykle przeglądów
- Lepsze opinie z procesu wdrażania od nowych pracowników
Te wskaźniki pokażą, czy Twoje konwencje poprawiają prędkość zespołu i czytelność kodu.
Najczęściej zadawane pytania o konwencje nazewnictwa
Jak zdobyć poparcie starszych programistów?
Skoncentruj się na korzyściach dla zespołu, a nie na osobistych preferencjach. Wykorzystaj dane z audytów lub pilotażowych refaktorów, aby pokazać konkretne poprawy w czytelności i czasie przeglądu. Uczyń to decyzją zespołową, a nie narzuconym z góry nakazem.
Jaka jest najlepsza konwencja nazewnictwa dla endpointów API?
Dla RESTful API używaj rzeczowników w liczbie mnogiej dla zasobów, a działania niech definiują metody HTTP. Przykład: GET /users, GET /users/{userId}, POST /users. Unikaj czasowników w URL-ach, aby API było przewidywalne i niezależne od języka.
Czy pliki testowe powinny mieć własne konwencje nazewnictwa?
Tak. Odbijaj nazwę komponentu lub modułu i dodaj .test.ts lub .spec.ts. Trzymaj testy obok plików, które obejmują, i pisz opisy testów tak, aby czytały się jak zdania po ludzku.
Szybkie Q&A — trzy zwięzłe odpowiedzi
P: Jaka jest jedna najważniejsza zasada nazewnictwa, od której zacząć?
A: Używaj camelCase dla zmiennych/funkcji, PascalCase dla typów/komponentów i UPPER_SNAKE_CASE dla prawdziwych stałych. Same te wskazówki znacznie zmniejszają zamieszanie.
P: Jak egzekwować nazewnictwo bez łamania buildu w istniejącym kodzie?
A: Skonfiguruj linting tak, by działał tylko na plikach staged i zmienionych (używając lint-staged i kontroli CI dla PR). To egzekwuje zasady dla nowej pracy, pozwalając jednocześnie na stopniowe poprawianie dziedziczonego kodu.
P: Jak konwencje nazewnictwa pomagają narzędziom AI, takim jak Copilot?
A: Spójne wzorce uczą AI intencji projektu, dzięki czemu sugestie są dokładniejsze, refaktory bezpieczniejsze, a generowany kod zgodny z przyjętymi w zespole konwencjami.
W Clean Code Guy pomagamy zespołom przyjmować praktyczne standardy i przeprowadzać audyty baz kodu oraz refaktory przygotowujące do pracy z AI, by przywrócić strukturę i szybkość zespołom inżynieryjnym. Dowiedz się więcej na https://cleancodeguy.com.
1.
Wyniki audytów i przykłady zespołów z wewnętrznych przeglądów baz kodu Clean Code Guy pokazujące powszechne niespójności nazewnictwa i ich wpływ: https://cleancodeguy.com
2.
Statistics Canada: przykład standaryzacji danych i redukcji błędów integracji: https://www150.statcan.gc.ca/n1/pub/12-001-x/2019001/article/00001-eng.htm
3.
CU Research Computing: najlepsze praktyki kodowania i zaobserwowane korzyści z jaśniejszego nazewnictwa: https://curc.readthedocs.io/en/latest/programming/coding-best-practices.html
4.
Ankieta i wewnętrzna analiza dotycząca nazewnictwa plików, konfliktów przy scalaniu i utrzymywalności na podstawie opinii menedżerów inżynieryjnych i audytów baz kodu: https://cleancodeguy.com
🙋🏻♂️
AI pisze kod.Ty sprawiasz, że przetrwa.
W erze przyspieszenia AI czysty kod to nie tylko dobra praktyka — to różnica między systemami, które się skalują, a bazami kodu, które zapadają się pod własnym ciężarem.