プログラミングにおける命名規則をマスターして、クリーンでスケーラブルなコードを実現する方法。TypeScript、React、Node 向けの実践ルール、自動化、展開戦略を紹介します。
February 4, 2026 (2mo ago)
クリーンでスケーラブルなコードのための命名規則ガイド
プログラミングにおける命名規則をマスターして、クリーンでスケーラブルなコードを実現する方法。TypeScript、React、Node 向けの実践ルール、自動化、展開戦略を紹介します。
← Back to blog
クリーンでスケーラブルなコードのための命名規則
命名規則をマスターすることで、よりクリーンでスケーラブルなコードが実現できます。実践的なルール、自動化、展開戦略を学びましょう。
はじめに
命名規則は単なるスタイルの選択以上のものです — それはコードを読みやすく、保守しやすく、変更に強くする共有言語です。適切な名前は認知的負荷を減らし、オンボーディングを速め、リンターからAIアシスタントまでの自動化を改善します。本ガイドでは TypeScript、React、Node に対する実践的なルールと、規約を定着させるための強制および展開戦略を紹介します。
なぜ命名規則はコードベースの第一の防御なのか
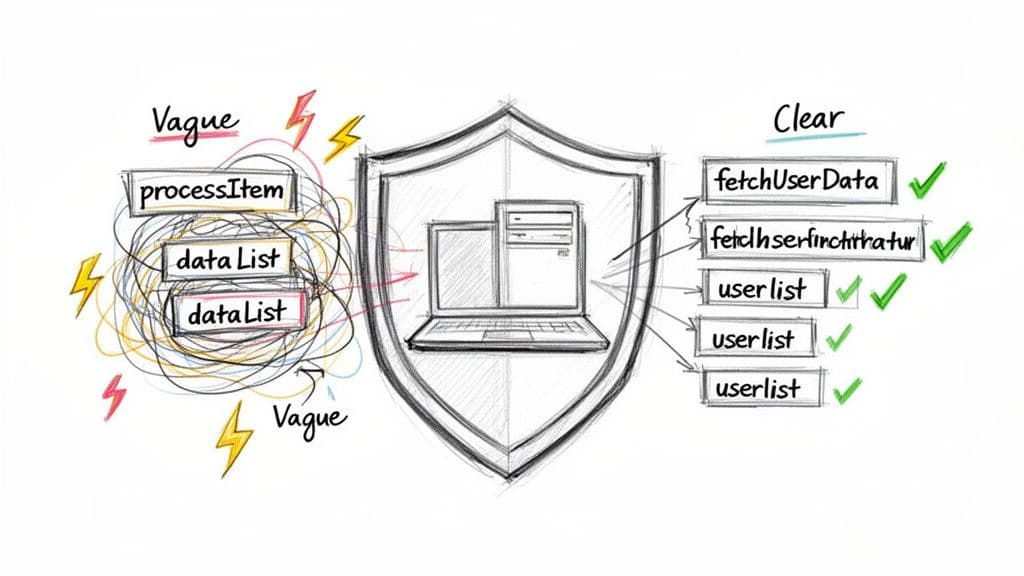
命名は美学の問題ではなく、明確なコミュニケーションの問題です。すべての変数、関数、コンポーネントはアプリの物語の一部です。あいまいまたは一貫性のない名前は、読者に立ち止まって文脈を探させ、小さな修正を時間の浪費に変えてしまいます。
一つの不明瞭な関数名だけで数分、あるいは数時間のデバッグの浪費を招くことがあります。それがチーム全体で頻発すると生産性は落ち、インシデントの発生確率が上がります。明確で一貫した命名がされたコードベースは実質的に「自己文書化」され、長大なコメントの必要性を減らし、システムのナビゲーションを容易にします。
悪い命名の現実世界でのコスト
Node.js のバックエンドで processItem() という関数と dataList という引数があるとします。実際に何をするのか?それを知るには実装を読んだり呼び出し元をたどったりデバッガを動かしたりしなければならないかもしれません。こうした寄り道は積み重なり、仮定が明確でない場合に実際の障害につながることがあります。
初期プロジェクトの監査では命名の不一致が広く見られ、オンボーディングやデバッグの遅延が計測可能であることが示され、命名がチームの速度と信頼性に与える影響を強調しました。1
カナダ統計局の事例も、一貫した標準が政府プロジェクトにおける統合エラーを減らすことを示しており、命名と標準化が大規模で重要であることを示しています。2
命名規約とチームのスケーラビリティ
チームが成長するにつれて問題は複利的に悪化します。一貫性のない命名は新入社員がコードを理解しにくくし、協力作業を遅らせます。早い段階で共有規約を採用することでレガシー負債を防ぎ、スケーリング時の摩擦を減らせます。
一目でわかる一般的な命名スタイル
このクイックリファレンスは一般的なケーススタイルと典型的な使用箇所を示します:
| ケーススタイル | 例 | 主な使用例 |
|---|---|---|
| camelCase | let userName = "Alex"; | 変数と関数(JavaScript/TypeScript) |
| PascalCase | class UserProfile {} | クラス、インターフェース、型、React コンポーネント |
| snake_case | const API_KEY = "..."; | 定数、または Python のような言語 |
| kebab-case | user-profile.css | CSS クラス名、ファイル名、URL |
どのスタイルをいつ使うかを理解することで、プロジェクト全体で予測可能な語彙が構築されます。
AI と協働するためにコードを準備する
GitHub Copilot や Cursor のような AI ツールは、一貫したコードで最もよく機能します。これらはコードベースからパターンを学習し、提案にそれを反映します。
- 予測可能な AI 提案:
isやhasで始まるブール変数は条件ロジックを明確にします。 - 正確な関数生成:データを取得する関数が一貫して
fetchSomethingのように命名されていれば、AI は正しい非同期コードを生成しやすくなります。 - より賢いリファクタリング:一貫性のある名前はツールが関係性を検出し、安全な変更を行いやすくします。
命名規約を明示することで、人間の可読性を高め、AI アシスタントをより信頼できる協働者にします。
TypeScript、React、Node に対する実践的命名ルール
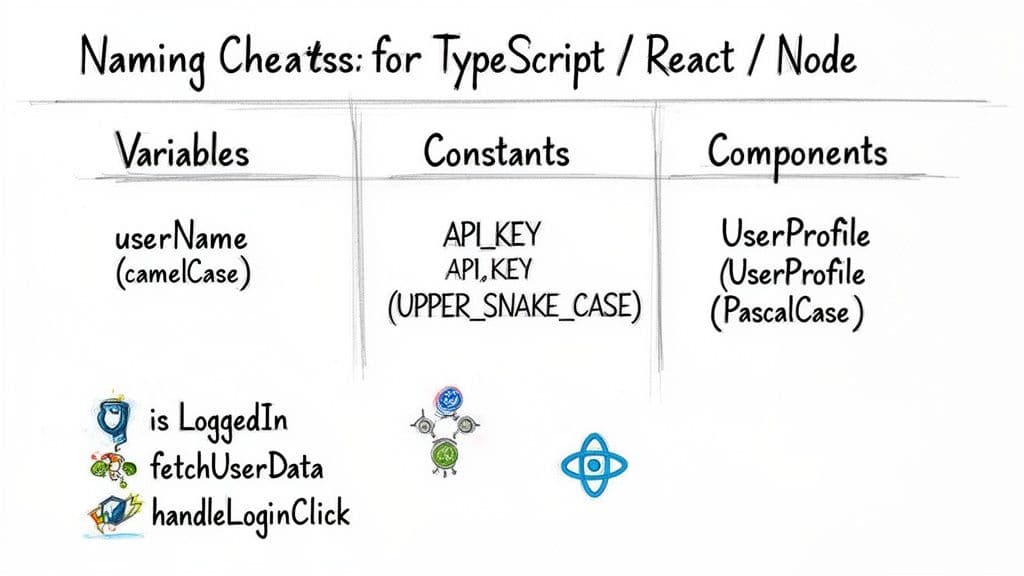
これらのルールはモダンな Web スタックで実戦に耐えるもので、チーム全体の認知負荷を減らします。
コアな JavaScript / TypeScript の規約
-
変数と関数:camelCase を使う
- Good:
let userProfile = {}; - Good:
function calculateTotalPrice() {} - Bad:
let UserProfile = {};(クラスのように見える)
- Good:
-
クラス、インターフェース、型:PascalCase を使う
- Good:
class AuthenticationService {} - Good:
interface User { id: string }
- Good:
-
真の定数:UPPER_SNAKE_CASE を使う
- Good:
const API_BASE_URL = '...' - Good:
const MAX_LOGIN_ATTEMPTS = 5;
- Good:
これらの基本を押さえることで識別子が即座に認識可能になります。
意味的命名による明確化
意図を示す語やプレフィックスを使いましょう。変数と関数の明確な区別はバグや誤解を減らします。調査や監査は、明示的な命名を採用するチームがバグ率を下げ、保守性を向上させていることを示しています。3
React 固有のルール
-
コンポーネントとファイル名:PascalCase を使う
function UserProfile() { ... }→ ファイルUserProfile.tsx
-
イベントハンドラ:
handleをプレフィックスにするfunction handleLoginClick() { ... }
-
useState のペア:
[thing, setThing]を踏襲するconst [isLoading, setIsLoading] = useState(false);
アクション志向で記述的な命名
- ブール:
is、has、canをプレフィックスにする(isModalOpen,hasUnsavedChanges) - 関数:動詞で命名する(
fetchUserData,validateInput,saveSettings)
英語の平易な文のように読める命名を採用すると、コードが直感的になりコメントの必要が減ります。
命名ルールを強制する自動化
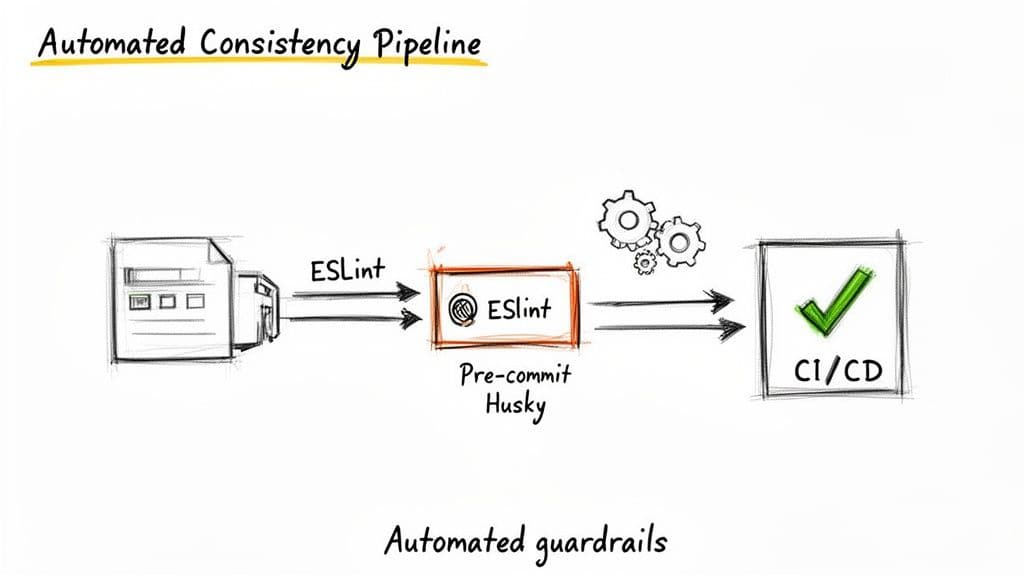
ルールを定義することが最初のステップであり、自動化がそれを定着させます。命名の一貫性をコードレビューだけに頼るとレビュワーの時間を浪費し、抜け穴が残ります。
ESLint:最初の防御線
ESLint はエディタ内でリアルタイムのフィードバックを提供し、カスタムルールやプラグインで命名規約を強制できます。共有の ESLint 設定を使えば、全員が同じチェックを受けられます。
- リアルタイムの修正によりコミット前にミスを防げる。
- チーム固有の規約(例:ブールのプレフィックス)を強制するルールを調整できる。
- 共有設定によりスタイル議論を減らし摩擦を軽減する。
Husky とプリコミットフック
Husky はコミット時にスクリプトを実行します。lint-staged と組み合わせることで、ステージされたファイルに対して ESLint を実行し、チェックに失敗したコミットを拒否して非準拠コードのリポジトリ流入を防げます。
CI 上のリンティング
最終ゲートとして CI で常にリンターを実行しましょう。CI は客観的な真実のソースとして機能し、命名違反やその他のスタイルエラーを含む PR をブロックします。
この 3 層のアプローチ — エディタ内リンティング、プリコミットフック、CI — により最小限の手作業で規約を強制できます。
ファイルとフォルダ構成の設計
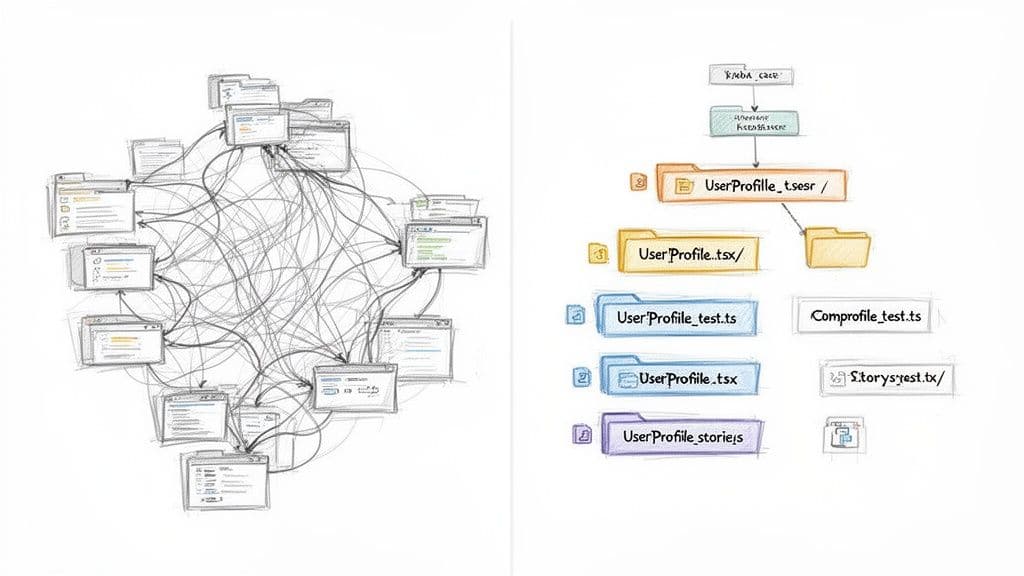
命名規約はファイルやディレクトリにも及びます。予測可能なアーキテクチャは新しい開発者がコードを素早く見つけられるようにし、変更時の認知負荷を減らします。
タイプ別ではなく機能別に構成する
コードをファイルタイプ別ではなく、機能やドメインごとに整理しましょう。コンポーネント、サービス、フック、テストを機能ごとに同じディレクトリに共置します。たとえば認証に関するすべてを /auth にまとめます。
これにより機能が自己完結的になり、理解、テスト、削除が容易になります。
必須のファイル命名ルール
- ディレクトリ:kebab-case を使う(
user-profile,auth-service) - React コンポーネント:PascalCase(
UserProfile.tsx) - ユーティリティとサービス:camelCase(
apiClient.ts,stringUtils.ts) - 説明的なサフィックスを使う(
.test.ts,.stories.tsx,.styles.ts)
一貫したファイルシステムはマージコンフリクトを減らし、分散チームの協業を助けます。
既存コードベースに新しい規約を展開する方法
全面的で即時のリファクタリングはリスキーです。代わりにインクリメンタルなアプローチを採用しましょう:常に見つけたコードを少しだけきれいにして残す、という姿勢です。
まずは対話から始める
測定可能な利点(オンボーディングの高速化、バグの減少、開発生産性の向上)を説明してチームの賛同を得ましょう。単一モジュールでパイロットを実施して成果を示し勢いをつけます。
ルールを文書化する
CONTRIBUTING.md やプロジェクトの README に規約を記載しましょう。正しい例と間違った例を明確に示します。ルールの理由を簡潔に説明しておくと定着しやすくなります。
リンターに重労働を任せる
ツールを設定して新規または変更されたコードにのみルールを適用するようにします:lint-staged、Husky、および PR 変更に限定した CI チェックを使います。これにより大きなレガシーファイルで作業を阻害せず、すべての新しい変更が標準に従うようにできます。
成功を測定する
以下のような指標を追跡しましょう:
- 命名に関する PR の指摘が減る
- レビューサイクルが速くなる
- 新入社員からのオンボーディングに関するフィードバックが改善する
これらの指標は規約がチームの速度とコードの明瞭性を改善しているかどうかを示します。
命名規約に関するよくある質問
どうやってシニア開発者の賛同を得るか?
個人の好みではなくチームレベルの利益に焦点を当てましょう。監査やパイロットリファクタのデータを使って、可読性やレビュー時間の具体的な改善を示します。トップダウンの命令ではなくチームで決める形にしましょう。
API エンドポイントにはどんな命名規約が最適か?
RESTful API ではリソースに複数形の名詞を使い、アクションは HTTP メソッドに任せましょう。例:GET /users, GET /users/{userId}, POST /users。URL に動詞を入れるのは避け、API を予測可能で言語に依存しないものにします。
テストファイルには独自の命名規約が必要か?
はい。コンポーネントやモジュール名を模して .test.ts または .spec.ts を付けましょう。テストは対象ファイルのそばに置き、テストの説明は人間の文のように読めるように書きます。
クイック Q&A — 簡潔な三つの答え
Q: 最初に取り組むべき最も影響力のある命名ルールは何?
A: 変数/関数には camelCase、型/コンポーネントには PascalCase、真の定数には UPPER_SNAKE_CASE を使うこと。これらの視覚的手がかりだけで混乱は劇的に減ります。
Q: レガシーコードを壊さずに命名を強制するには?
A: ステージされたファイルや変更されたファイルに対してのみリンティングを実行するよう設定する(lint-staged と PR 向けの CI チェックを使用)。これにより新規作業には規約を適用しつつ、レガシーコードは段階的に改善できます。
Q: Copilot のような AI ツールに命名規約はどう役立つか?
A: 一貫したパターンはプロジェクトの意図を AI に教えるので、提案がより正確になり、リファクタリングが安全になり、生成コードがチームの確立した規約に従いやすくなります。
At Clean Code Guy, we help teams adopt practical standards and run Codebase Audits and AI-Ready Refactors to bring structure and speed back to engineering teams. Learn more at https://cleancodeguy.com.
1.
監査結果とチーム事例:Clean Code Guy の内部コードベースレビューから得られた、一般的な命名不一致とその影響の例:https://cleancodeguy.com
2.
Statistics Canada:データ標準化と統合エラー削減の事例:https://www150.statcan.gc.ca/n1/pub/12-001-x/2019001/article/00001-eng.htm
3.
CU Research Computing:コーディングベストプラクティスと、明確な命名規約による利点の観察:https://curc.readthedocs.io/en/latest/programming/coding-best-practices.html
4.
ファイル命名、マージコンフリクト、保守性に関する調査と内部分析(エンジニアリングマネージャのフィードバックと Codebase Audits):https://cleancodeguy.com
🙋🏻♂️
AIがコードを書きます。あなたがそれを長持ちさせます。
AI加速の時代において、クリーンコードは単なる良い実践ではありません—スケールするシステムと自らの重みで崩壊するコードベースの違いです。