Rubyのハッシュマップ(Hash)を極め、よりクリーンで高速、スケーラブルなコードを書く方法。内部構造、パフォーマンス、ベストプラクティスを深掘りします。
January 30, 2026 (3mo ago)
Rubyでハッシュマップを極めて、クリーンでスケーラブルなコードを実現する
Rubyのハッシュマップ(Hash)を極め、よりクリーンで高速、スケーラブルなコードを書く方法。内部構造、パフォーマンス、ベストプラクティスを深掘りします。
← Back to blog
Title: Rubyでハッシュマップを極めて、クリーンでスケーラブルなコードを実現する Description: Rubyのハッシュマップ(Hash)を極め、よりクリーンで高速、スケーラブルなコードを書く方法を発見してください。内部構造、パフォーマンス、ベストプラクティスへの深掘り。 Tags: hashmap in ruby, ruby hash, clean ruby code, ruby performance, ruby refactoring Content: Rubyにおける「hashmap」という用語に馴染みがあるなら、実際にはRuby組み込みのHashクラスについて話しています。この強力なキーと値のストアは、デジタルなファイルキャビネットのように機能します:すべてのデータ片に一意のラベルが付けられ、ほぼ瞬時に再び見つけられるようになります。
RubyのHashを極めることがコードの書き方を変える理由
根本的に、RubyのHashは一意のキーとそれに対応する値の集合です。辞書のように考えてください:単語(キー)を引いてその定義(値)を見つけます。ハッシュはウェブアプリのセッションデータから設定情報まであらゆる場所で使われ、挿入や検索がほぼ一定時間で高速に行える点が特長です1。
Hashを使いこなすということは、単に構文を覚える以上の意味があります。よりクリーンで直接的なコーディングスタイルを採用することを意味します。長く広がるif/else連鎖の代わりに、単純なキー検索でロジックを置き換えられることが多くあります。これにより複雑さが減り、可読性が向上し、保守が容易になります。
このガイドでは、RubyのHashがどのように動作するか、慣用的な使い方と落とし穴、実践的なレシピ、Hashが最適でない場合の代替手段、そして今日から適用できるリファクタリングパターンを解説します。
RubyのHashは内部でどう動いているか
RubyのHashはハッシュテーブルの最適化されたCによる実装です。キーと値のペアを追加すると、Rubyはキーをハッシュ関数に通してハッシュコードを計算します。そのコードは内部配列のバケットインデックスにマップされ、Rubyは項目を一つずつ走査する代わりに直接正しいスロットにジャンプできます1。
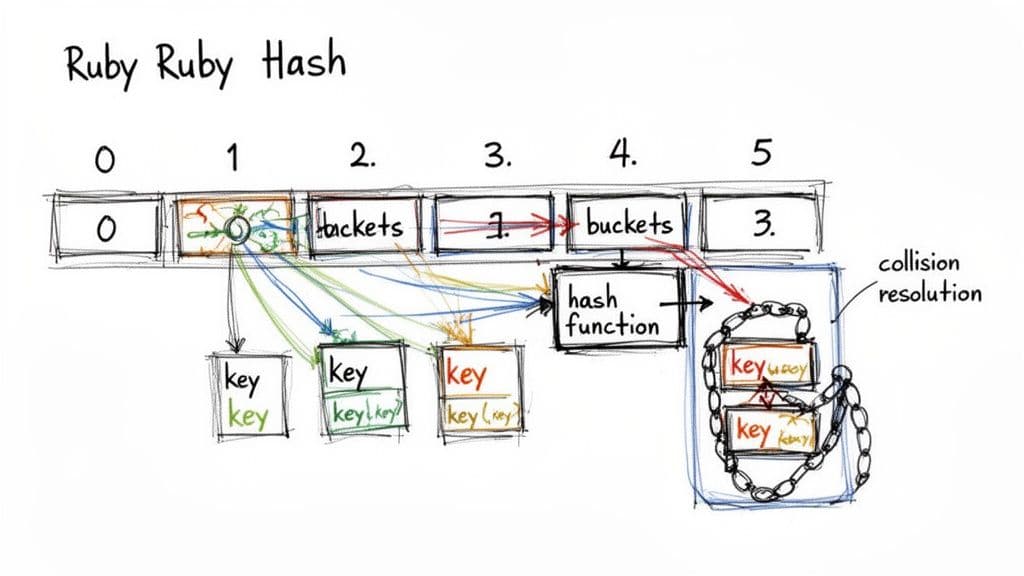
ハッシュ関数、バケット、衝突
ハッシュ関数は任意のキーを数値のハッシュコードに還元し、それがバケットインデックスに変換されます。同じインデックスにマップされるとき、つまり衝突は通常発生します。Rubyは各バケットに複数のエントリを格納し、必要に応じてその小さなリストを走査します。最近のRubyの最適化はその走査を小さく高速に保つようになっています。
Ruby 2.4では、データ局所性とリサイズ挙動を改善する大きな内部変更が導入され、一般的なワークロードで大幅な速度向上がもたらされました2。
慣用的なHashの使用法とよくある落とし穴
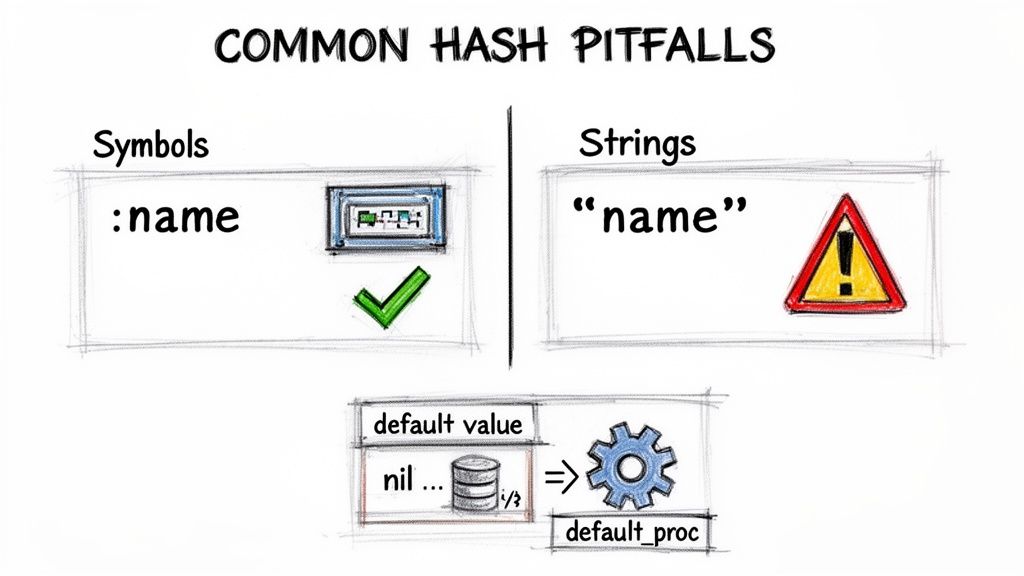
理論を知ることは有用ですが、本番環境でHashを有効活用するには微妙なバグを避け、予測可能なコードを書くことが必要です。
シンボルと文字列のキー
シンボルと文字列は見た目は似ていますが、振る舞いが異なります。シンボルは不変で再利用されますが、文字列は毎回新しいオブジェクトを生成します。シンボルは通常、比較がオブジェクト同一性で行えるため、キーとして高速でメモリ効率が良いです3。
一般的なバグは、データが文字列キーを使っているときにシンボルキーを期待してしまうことです(例えば受信したウェブパラメータ)。symbolize_keysやstringify_keysで受信キーを統一するなど、一貫した規約を使用してこの不一致を避けてください。
デフォルト値とデフォルトproc
存在しないキーにアクセスするとnilが返り、それに対してメソッドを呼ぶとNoMethodErrorを引き起こす可能性があります。驚きを避けるためにデフォルト値を使いましょう:
# Safe default
fruit_counts = Hash.new(0)
fruit_counts["apple"] = 5
fruit_counts["orange"] # => 0
より高度な挙動のために、デフォルトprocを使うと値を遅延計算または初期化できます。
merge と merge!
mergeは新しいHashを返し、元のHashを保持します。merge!は破壊的に変更します。副作用を避けてデータフローを予測可能に保ちたいときは、非破壊的なメソッドを優先してください。
不変性のためのfreeze
変更してはならない定数や設定には.freezeを呼んで偶発的な変更を防ぎます:
CONFIG = { api_key: "abc-123", timeout: 5000 }.freeze
# CONFIG[:timeout] = 3000 # raises FrozenError
実践的なRuby Hashクックブック
このセクションは一般的なタスクのレシピ集です。
反復と変換
eachで反復し、select、reject、map、to_hでフィルタや変換をきれいに行います:
user_permissions = { admin: true, editor: true, viewer: false }
active_roles = user_permissions.select { |role, has_access| has_access }
role_descriptions = user_permissions.map { |role, has_access| [role, "Can perform #{role} actions: #{has_access}"] }.to_h
digでネストされたデータを安全に辿る
digはネストされたハッシュを辿るときのNoMethodErrorを防ぎます:
api_response = { user: { profile: { name: "Alice" } } }
email = api_response.dig(:user, :profile, :email) # => nil
name = api_response.dig(:user, :profile, :name) # => "Alice"
キー/値のクリーンアップと変換
compact、transform_keys、transform_valuesを使うとデータの整形やサニタイズが簡潔で読みやすくなります:
messy_data = { "firstName" => "bob", "lastName" => "smith", "age" => 30 }
clean_data = messy_data
.transform_keys(&:to_sym)
.transform_values { |v| v.is_a?(String) ? v.capitalize : v }
# => { firstName: "Bob", lastName: "Smith", age: 30 }
適切なツールの選択
Hashは柔軟ですが、常に最適な選択とは限りません。固定スキーマにはStructを使い、予測できないキーでドット表記が欲しい場合はOpenStructを(ただしパフォーマンスコストに注意)、一意性チェックにはSetを使ってください—Setはメンバシップテストに最適化され、Rubyのコア構造上に構築されています4。
適切な構造を選ぶと、コードは速く、明確に、保守しやすくなります。
クイック比較
| 構造 | 最適用途 | 利点 | 考慮点 |
|---|---|---|---|
| Hash | 動的なキーと値のデータ | 圧倒的な柔軟性 | メモリ消費が多い;キーのタイプミスの可能性 |
| Struct | 小さく固定された属性セット | メモリ効率が良い;メソッドアクセス | 柔軟性に欠ける |
| OpenStruct | プロトタイピング、不確定なキー | ドット表記の利便性 | 遅い;メモリ消費が大きい |
| Set | 高速な一意性チェック | O(1)のメンバシップテスト | 値に対応する値は持たない |
Hashパターンによるリファクタリング
長いif/elsifやcase連鎖を、データをルックアップテーブルに移すことでHashで置き換えましょう。これによりデータとロジックが分離され、新しいケースの追加は単にキーを追加するだけで済みます。
ENDPOINTS = {
development: "http://dev.api.example.com",
staging: "http://staging.api.example.com",
production: "https://api.example.com"
}.freeze
def get_api_endpoint(environment)
ENDPOINTS.fetch(environment, "http://localhost:3000")
end
オプションハッシュは、任意のパラメータを単一の拡張可能な引数にまとめることでメソッドシグネチャを簡素化します。
よくある質問
RubyのHashはhashmapと同じですか?
はい。hashmapは一般的な計算機科学用語であり、Rubyではクラス名がHashで、そのデータ構造の典型的な時間計算量特性を実装しています1。
Hashで避けるべき一般的な間違いは何ですか?
最も頻繁なミスはシンボルと文字列キーを混在させることです。通常は内部キーにシンボルを使う規約を確立して外部入力を早期に正規化してください。
Hashの使用はRailsのパフォーマンスにどう影響しますか?
HashはRailsの至る所にあります:params、セッションデータ、JSON処理。非効率なHashの生成や繰り返しの重い操作はメモリ膨張やリクエストの遅延を引き起こします。ホットスポットをプロファイルし、適切な場所ではインプレースや遅延パターンを優先してください。
クイックQ&A — 開発者によくある質問
Q: ネストしたキーにアクセスするときのnilエラーをどう避けますか?
A: digを使うか、Hash.new(default)やデフォルトprocで安全なデフォルトを提供してください。
Q: いつHashからStructやSetに切り替えるべきですか?
A: フィールドが固定で既知ならStructを使い、一意性と高速なメンバシップチェックだけが必要ならSetを使ってください。
Q: 複数ソースからの設定を安全にマージするには?
A: 非破壊のmergeを優先し、最終的な設定をfreezeしてください。インプレースで更新が必要ならmerge!を注意して使い、副作用を文書化してください。
At Clean Code Guy, our mission is to help teams turn complicated codebases into assets that are easy to maintain and scale. We dive deep into principles like these to help you ship better software, faster. See how we can help you build a resilient, AI-ready application at cleancodeguy.com.
1.
Wikipedia, "Hash table." https://en.wikipedia.org/wiki/Hash_table
2.
Ruby Issue Tracker, "Hash improvement (power-of-two, data locality)". https://bugs.ruby-lang.org/issues/12142
3.
Ruby Guides, "Symbols in Ruby". https://www.rubyguides.com/2019/03/ruby-symbols/
4.
Ruby Standard Library Documentation, Set. https://ruby-doc.org/stdlib-2.7.0/libdoc/set/rdoc/Set.html
🙋🏻♂️
AIがコードを書きます。あなたがそれを長持ちさせます。
AI加速の時代において、クリーンコードは単なる良い実践ではありません—スケールするシステムと自らの重みで崩壊するコードベースの違いです。