関数型プログラミング(FP)とオブジェクト指向(OOP)は設計・テスト・保守に直接影響します。本記事では両者の主要な違いと実務での判断軸、段階的なハイブリッド導入手順を具体的に示し、チームとプロジェクトに合った選択を支援します。
November 27, 2025 (5mo ago) — last updated April 1, 2026 (1mo ago)
関数型プログラミング vs OOP:実務での選び方
FPとOOPの違い、利点、段階的なハイブリッド導入手順を実務視点で解説。保守性、並列性、テスト性で最適な判断を導きます。
← Back to blog
関数型プログラミング vs OOP:実務での選び方
概要: 関数型プログラミング(FP)とオブジェクト指向プログラミング(OOP)を比較し、スケーラビリティ、保守性、チーム生産性に応じた選択肢と段階的導入の方法を示します。実務での判断基準と導入手順を分かりやすく解説します。1
はじめに
関数型プログラミング(FP)とオブジェクト指向プログラミング(OOP)の選択は、ソフトウェア設計、テスト、保守に直結します。本ガイドでは、両パラダイムのコアな違い、実践的なトレードオフ、ハイブリッド導入の手順を提示し、プロジェクトとチームに最適な道筋を示します。実例や業界の報告を参照し、根拠のある判断を支援します。2
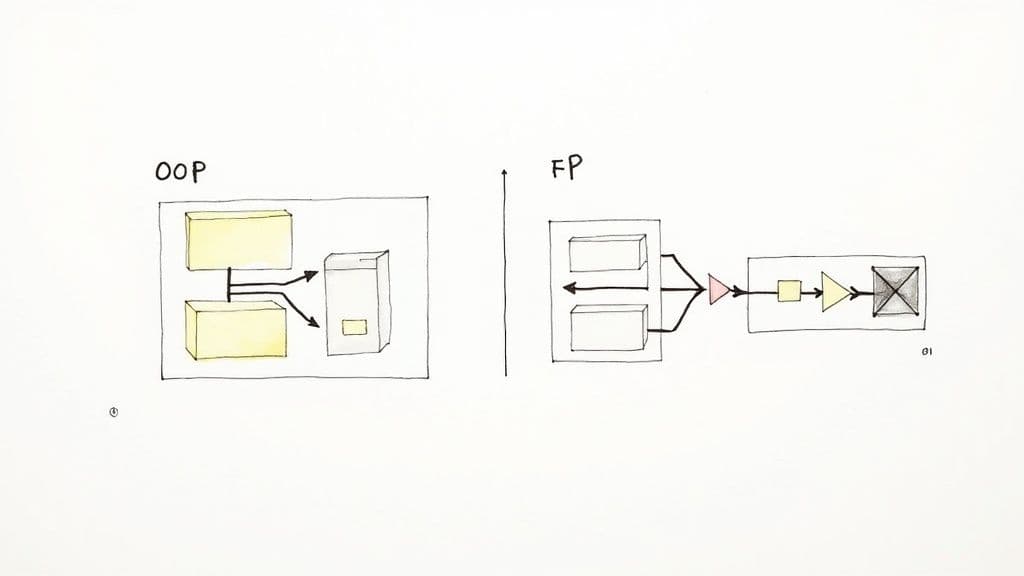
どちらを選ぶか:実務的な判断軸
選ぶパラダイムはアーキテクチャ、開発者体験、テスト戦略、長期的な保守性に影響します。現場では、境界部分にOOPを使い、データ変換にはFPを使うハイブリッドがよく採られています。以下を出発点に、プロジェクト要件とチームの経験を照らし合わせてください。2
- エンタープライズアプリケーションや複雑なGUI:OOPが有利。状態と振る舞いを1つのエンティティにまとめやすいため、UIコンポーネントやドメインモデルの設計が直感的になります。
- データパイプラインや並列処理:FPが有利。不変性と純粋関数により並列化や再現性が向上します。
クイック参照:どのパラダイムから始めるか
| シナリオ | 推奨パラダイム | 理由 |
|---|---|---|
| 複雑なGUIで多くの状態を扱う場合 | OOP | カプセル化により各コンポーネントが自身の状態を管理しやすい。 |
| 大規模な業務ドメイン | OOP | ビジネスエンティティと関係を自然に表現できる。 |
| データ処理パイプライン/ETL | FP | 不変性と純粋関数で並列化と予測可能性が高まる。 |
| リアルタイム並行処理(例:チャットサーバ) | FP | 共有ミュータブル状態を避けることで競合を減らせる。 |
| 単一のソース・オブ・トゥルース(状態ツリー等) | FP | 不変の状態ツリーは再現性とデバッグを簡単にする。 |
| クラスベース言語に慣れたチーム | OOP | 学習コストが低く初期の生産性が高い。 |
多くのチームは上位の構造にOOPを用い、コアのデータ変換にはFPを適用するハイブリッドで最良の結果を得ています。実際の採用例や報告はこの傾向を裏付けます。3
OOPとFPのコア原則
オブジェクト指向設計はデータと振る舞いをオブジェクトに束ね、カプセル化、継承、多態性で複雑さを管理します。教育や多くのエンタープライズ環境で主流の考え方です。1
関数型は純粋関数、不変性、最小限の副作用を重視します。テストしやすく再現性のあるコードを実現し、並列処理やデータ変換で効果を発揮します。2
実践的比較:状態とデータの扱い
差異の核心は変更の扱いです:
- OOPは可変状態をオブジェクト内にカプセル化し、メソッドで更新します。現実世界のモデリングに近い反面、並行処理やテストの難易度が上がることがあります。
- FPはデータを不変とし、純粋関数で変換して新しい値を返します。パイプライン的な処理は推論と並列化を単純化します。
近年、データ中心の領域でFPの採用が増えていることがコミュニティ調査でも示されています。設計上のメリットを実証したケーススタディも存在します。34
サイドバイサマリー
| 概念 | OOP | FP |
|---|---|---|
| 基本単位 | 状態と振る舞いをもつオブジェクト | 純粋関数と不変データ |
| 状態の扱い | 可変でカプセル化 | 不変、変換は新しいデータを生成 |
| データフロー | オブジェクトがメソッドを呼び状態を変更 | データが関数パイプラインを流れる |
| 並行性 | 共有状態の同期が必要 | 不変性により並行処理が容易 |
| 目的 | 実世界のエンティティをモデル化 | 宣言的にデータ変換を記述 |
いつOOPを使い、いつFPを使うか
状態と振る舞いを持つエンティティが中心ならOOP。予測可能な変換や並列処理、テスト容易性が重要ならFPを選びます。多くのチームは両者を組み合わせ、上位の設計にクラスを使い、コアロジックは純粋関数で実装します。
実例として、フィンテック領域の一部チームはデータ処理にFPパターンを導入し、バッチ処理の安定性や保守性が改善した報告があります。導入効果はワークロードと設計に依存しますので、段階的な評価が重要です。4
ハイブリッド導入のステップ
段階的に関数型のパターンを導入する実践的手順:
- 命令型ループをmap、filter、reduceといった宣言的メソッドに置き換える。
- 中核のビジネスロジックを純粋関数に抽出し、再利用性とテスト性を高める。
- 上位のオーケストレーションやドメインモデルはオブジェクトに残し、データ変換はFPで処理する。
この方法なら全面的な書き換えリスクを避けつつ保守性を向上できます。社内ではクリーンコードやアーキテクチャのガイドラインを作り、パターンを標準化してください。関連ガイドは次のリンクを参照してください:/guides/clean-coding-principles と /resources/architecture。
よくある質問(FAQ)
Q1: 一つのパラダイムだけを選ぶべきですか?
いいえ。多くのチームはパラダイムを混在させます。アーキテクチャにはOOPを、コアロジックやデータ変換にはFPを使うことで、馴染みやすさと予測可能性のバランスを取ります。
Q2: FPは常に高速でメモリ効率が良いですか?
必ずしもそうではありません。不変性はコピーやアロケーションを増やすことがありますが、適切なデータ構造やランタイム最適化によりオーバーヘッドを抑えられます。パフォーマンスは実装とワークロード次第です。
Q3: OOPからFPへ移行する最初の一歩は?
コアロジックを純粋関数に分離し、ループを宣言的な配列メソッドに置き換え、小さな単位でテストを書いて段階的にリファクタリングしてください。
追加のQ&A(要点)
Q: どちらがチームにとって学習コストが低いですか? A: クラスベース言語に慣れているチームはOOPの方が学習コストが低いです。FPは概念の理解に時間が必要ですが、習得するとバグを減らす効果があります。
Q: パフォーマンスが心配な場合の判断基準は? A: ワークロードが大量の短時間処理であればFPの並列化メリットを評価し、リアルタイム遅延が厳しい場合は実装ごとにベンチを取って判断してください。
Q: 小さなプロジェクトではどちらを選ぶべきですか? A: 小さなプロジェクトではチームの慣れと速い実装が優先です。将来的な拡張や並列処理を見越すならFPのパターンを一部取り入れる価値があります。
まとめのQ&A(短く実践的)
Q: すぐに使える目安は? A: GUIや複雑なドメインはOOP、データ処理や並列性重視はFPを優先してください。
Q: ハイブリッドにする際の最初の作業は? A: 既存のループをmap/filterに置き換え、テストを増やして純粋関数を徐々に導入します。
Q: 採用判断をどう検証する? A: 小さなベンチマークとケーススタディで機能性・パフォーマンス・保守性を評価し、定量的な指標で判断してください。
さらに読むための資料と内部リソース
- Clean coding and architecture guide: /guides/clean-coding-principles
- Case studies on performance improvements: /case-studies/fintech-performance
- Architecture patterns and hybrid designs: /resources/architecture
1.
Project Euclid, “Object-Oriented Programming, Functional Programming, and R,” [https://projecteuclid.org/journals/statistical-science/volume-29/issue-2/Object-Oriented-Programming-Functional-Programming-and-R/10.1214/13-STS452.pdf]
2.
Scalac.io, “Functional Programming vs OOP,” [https://scalac.io/blog/functional-programming-vs-oop/]
3.
State of JS and community surveys report increased use of functional patterns in data-heavy projects; overview: [https://stateofjs.com/]
4.
Dev.to case study and community reports on paradigm shifts: Ben’s article, “OOP vs Functional Programming,” [https://dev.to/ben/oop-vs-functional-programming-5ej4]
🙋🏻♂️
AIがコードを書きます。あなたがそれを長持ちさせます。
AI加速の時代において、クリーンコードは単なる良い実践ではありません—スケールするシステムと自らの重みで崩壊するコードベースの違いです。