Scopri come padroneggiare l'hashmap in Ruby (Hash) per un codice più pulito, veloce e scalabile. Un'immersione profonda in internals, prestazioni e best practice.
January 30, 2026 (3mo ago)
Padroneggiare l'Hashmap in Ruby per un codice pulito e scalabile
Scopri come padroneggiare l'hashmap in Ruby (Hash) per un codice più pulito, veloce e scalabile. Un'immersione profonda in internals, prestazioni e best practice.
← Back to blog
If sei familiare con il termine hashmap in Ruby, in realtà stai parlando della classe incorporata Hash di Ruby. Questo potente archivio chiave-valore funziona come un mobiletto di archiviazione digitale: ogni pezzo di dati riceve un'etichetta unica così puoi ritrovarlo quasi istantaneamente.
Perché padroneggiare l'Hash di Ruby cambia il tuo modo di programmare
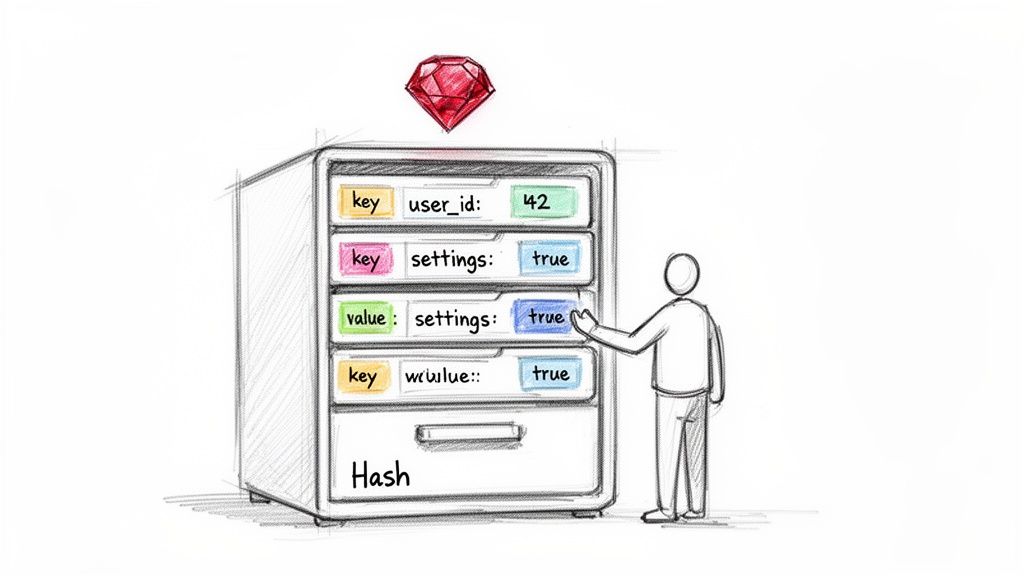
Al suo interno, un Hash di Ruby è una collezione di chiavi uniche e dei loro valori. Pensalo come un dizionario: cerchi una parola (la chiave) per trovare la sua definizione (il valore). Gli Hash sono usati ovunque — dai dati di sessione nelle applicazioni web alla configurazione — e brillano grazie a operazioni veloci, a tempo quasi costante, per inserimenti e ricerche1.
Diventare bravo con gli Hash significa più che imparare la sintassi. Significa adottare uno stile di programmazione più pulito e diretto. Al posto di lunghe catene di if/else, spesso puoi sostituire la logica con una semplice ricerca per chiave. Questo porta a una riduzione della complessità, una migliore leggibilità e una manutenzione più semplice.
Questa guida esplora come funziona l'Hash di Ruby, l'uso idiomatico e le insidie, ricette pratiche, alternative quando un Hash non è la scelta migliore e pattern di refactoring che puoi applicare oggi.
Come funziona un Hash di Ruby sotto il cofano
Un Hash di Ruby è un'implementazione ottimizzata in C di una tabella hash. Quando aggiungi una coppia chiave-valore, Ruby passa la chiave attraverso una funzione di hash per calcolare un codice hash. Quel codice viene mappato a un indice di bucket in un array interno, permettendo a Ruby di saltare direttamente allo slot giusto invece di scorrere gli elementi uno a uno1.
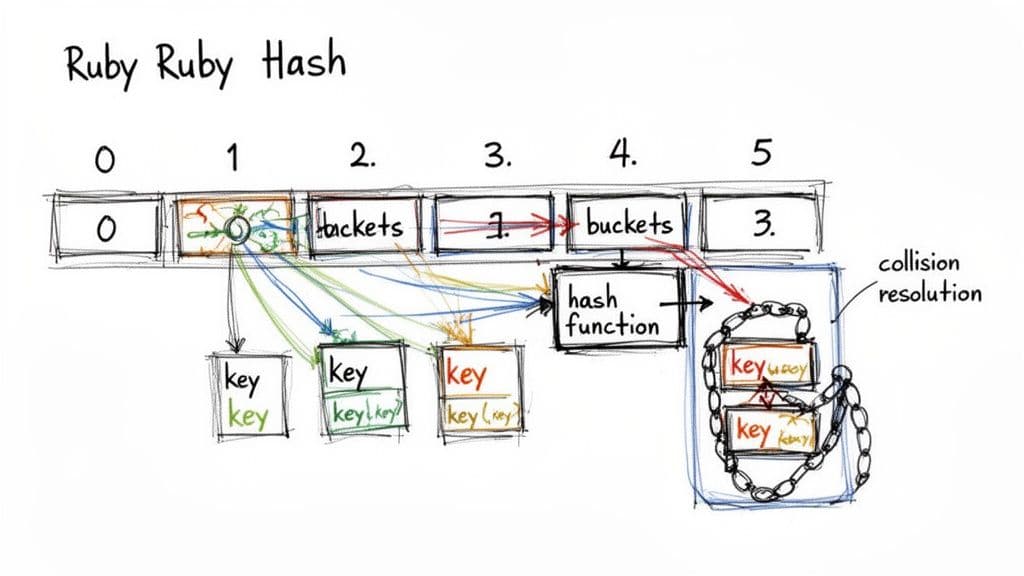
Funzione di hash, bucket e collisioni
La funzione di hash riduce qualsiasi chiave a un codice numerico di hash, che viene poi convertito in un indice di bucket. Le collisioni — quando due chiavi mappano allo stesso indice — sono normali. Ruby memorizza più voci per bucket e scorre la piccola lista quando necessario. Le ottimizzazioni recenti di Ruby mantengono quella scansione piccola e veloce.
Ruby 2.4 ha introdotto importanti cambiamenti interni che hanno migliorato le prestazioni degli hash aumentando la località dei dati e il comportamento di ridimensionamento; tali cambiamenti hanno fornito miglioramenti significativi di velocità nei carichi di lavoro comuni2.
Uso idiomatico dell'Hash e insidie comuni
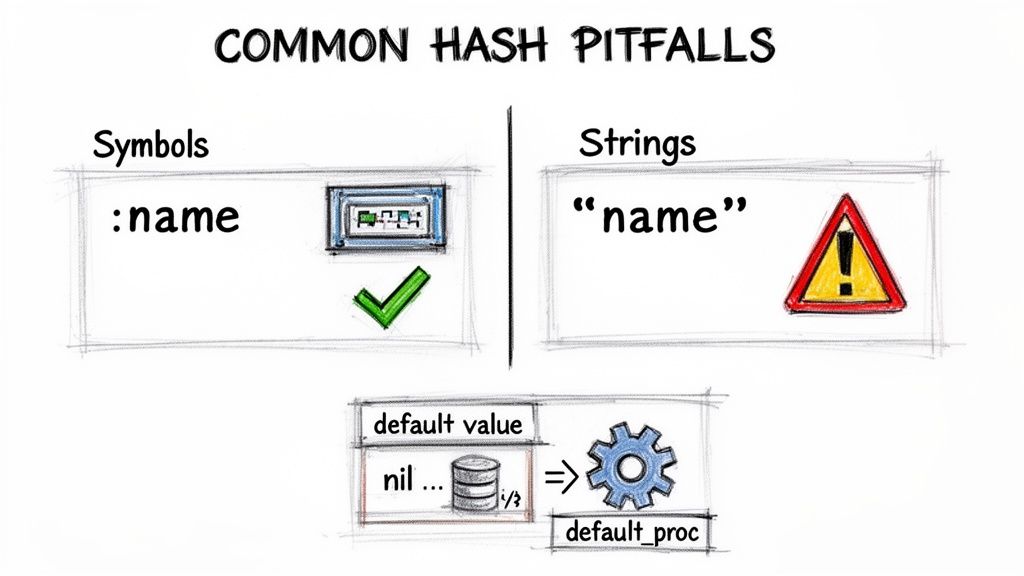
Conoscere la teoria è utile, ma far funzionare gli Hash in produzione significa evitare bug sottili e scrivere codice prevedibile.
Chiavi Symbol vs String
Symbol e String possono sembrare simili, ma si comportano diversamente. Un Symbol è immutabile e riutilizzato, mentre una String crea un nuovo oggetto ogni volta. I Symbol sono tipicamente più veloci e più efficienti in termini di memoria per le chiavi, perché i confronti possono essere fatti per identità dell'oggetto anziché carattere per carattere3.
Un errore comune è aspettarsi una chiave Symbol quando i dati usano chiavi String (per esempio, parametri web in ingresso). Usa convenzioni coerenti — converti le chiavi in ingresso con symbolize_keys o stringify_keys — per evitare questo disallineamento.
Valori predefiniti e default proc
L'accesso a una chiave inesistente restituisce nil, il che può causare NoMethodError quando chiami metodi su di esso. Usa un valore predefinito per evitare sorprese:
# Safe default
fruit_counts = Hash.new(0)
fruit_counts["apple"] = 5
fruit_counts["orange"] # => 0
Per comportamenti più avanzati, un default proc ti permette di calcolare o inizializzare i valori in modo lazy.
Merge vs merge!
merge restituisce un nuovo Hash e preserva l'originale. merge! muta in place. Preferisci metodi non distruttivi quando vuoi evitare effetti collaterali e mantenere il flusso dei dati prevedibile.
Freezing per l'immutabilità
Per costanti e impostazioni che non devono cambiare, chiama .freeze per prevenire mutazioni accidentali:
CONFIG = { api_key: "abc-123", timeout: 5000 }.freeze
# CONFIG[:timeout] = 3000 # raises FrozenError
Ricettario pratico per Hash in Ruby
Questa sezione è una raccolta di ricette per compiti comuni.
Iterazione e trasformazione
Usa each per iterare e select, reject, map e to_h per filtrare e trasformare in modo pulito:
user_permissions = { admin: true, editor: true, viewer: false }
active_roles = user_permissions.select { |role, has_access| has_access }
role_descriptions = user_permissions.map { |role, has_access| [role, "Can perform #{role} actions: #{has_access}"] }.to_h
Navigare in modo sicuro dati annidati con dig
dig previene NoMethodError quando si attraversano hash annidati:
api_response = { user: { profile: { name: "Alice" } } }
email = api_response.dig(:user, :profile, :email) # => nil
name = api_response.dig(:user, :profile, :name) # => "Alice"
Pulire e trasformare chiavi/valori
compact, transform_keys e transform_values rendono il rimodellamento e la sanitizzazione dei dati concisi e leggibili:
messy_data = { "firstName" => "bob", "lastName" => "smith", "age" => 30 }
clean_data = messy_data
.transform_keys(&:to_sym)
.transform_values { |v| v.is_a?(String) ? v.capitalize : v }
# => { firstName: "Bob", lastName: "Smith", age: 30 }
Scegliere lo strumento giusto
Un Hash è flessibile, ma non è sempre la scelta migliore. Per schemi fissi usa Struct; per notazione a punti con chiavi imprevedibili usa OpenStruct (ma considera il costo in termini di prestazioni); per controlli di unicità usa Set — che è ottimizzato per test di appartenenza e costruito sulle strutture core di Ruby4.
Quando scegli la struttura giusta, il tuo codice diventa più veloce, più chiaro e più facile da mantenere.
Confronto rapido
| Structure | Best for | Advantage | Consideration |
|---|---|---|---|
| Hash | Dynamic key-value data | Ultimate flexibility | More memory; potential key typos |
| Struct | Small, fixed attribute sets | Memory efficient; method access | Inflexible |
| OpenStruct | Prototyping, unpredictable keys | Dot-notation convenience | Slower; high memory |
| Set | Fast uniqueness checks | O(1) membership tests | No associated values |
Refactoring con pattern basati su Hash
Usa gli Hash per sostituire lunghe catene if/elsif o case spostando i dati in una tabella di lookup. Questo separa i dati dalla logica e rende l'aggiunta di nuovi casi semplice come aggiungere una chiave.
ENDPOINTS = {
development: "http://dev.api.example.com",
staging: "http://staging.api.example.com",
production: "https://api.example.com"
}.freeze
def get_api_endpoint(environment)
ENDPOINTS.fetch(environment, "http://localhost:3000")
end
Gli Options Hash semplificano anche le firme dei metodi raggruppando i parametri opzionali in un singolo argomento estendibile.
Domande frequenti
Un Hash di Ruby è la stessa cosa di una hashmap?
Sì. hashmap è il termine generico in informatica; in Ruby la classe si chiama Hash e implementa una tabella hash con le caratteristiche di complessità temporale tipiche della struttura dati1.
Qual è l'errore comune da evitare con gli Hash?
L'errore più frequente è mescolare chiavi Symbol e String. Stabilisci e applica una convenzione — tipicamente Symbol per chiavi interne — e normalizza l'input esterno precocemente.
Come influisce l'uso degli Hash sulle prestazioni in Rails?
Gli Hash sono ovunque in Rails: params, dati di sessione e gestione JSON. Creazioni inefficaci di Hash e operazioni pesanti ripetute possono causare aumento della memoria e rallentare le richieste. Profila i punti caldi e preferisci pattern in-place o lazy quando appropriato.
Domande rapide — Domande comuni degli sviluppatori
Q: Come evito errori nil quando accedo a chiavi annidate?
A: Usa dig o fornisci valori predefiniti con Hash.new(default) o un default proc.
Q: Quando dovrei passare da Hash a Struct o Set?
A: Usa Struct quando i campi sono fissi e noti; usa Set quando hai solo bisogno di unicità e controlli veloci di appartenenza.
Q: Come posso unire in modo sicuro configurazioni provenienti da più sorgenti?
A: Preferisci merge non distruttivo e congela la configurazione finale. Se hai bisogno di aggiornamenti in place, usa merge! con cautela e documenta gli effetti collaterali.
At Clean Code Guy, la nostra missione è aiutare i team a trasformare codebase complicati in asset facili da mantenere e scalare. Approfondiamo principi come questi per aiutarti a rilasciare software migliore, più velocemente. Scopri come possiamo aiutarti a costruire un'app resiliente e pronta per l'AI su cleancodeguy.com.
1.
Wikipedia, "Hash table." https://en.wikipedia.org/wiki/Hash_table
2.
Ruby Issue Tracker, "Hash improvement (power-of-two, data locality)". https://bugs.ruby-lang.org/issues/12142
3.
Ruby Guides, "Symbols in Ruby". https://www.rubyguides.com/2019/03/ruby-symbols/
4.
Ruby Standard Library Documentation, Set. https://ruby-doc.org/stdlib-2.7.0/libdoc/set/rdoc/Set.html
🙋🏻♂️
L'AI scrive codice.Tu lo fai durare.
Nell'era dell'accelerazione AI, il codice pulito non è solo una buona pratica — è la differenza tra sistemi che si scalano e codebase che collassano sotto il loro stesso peso.