Esplora la programmazione funzionale vs OOP per capire quale paradigma è migliore per il tuo team. Scopri come costruire software scalabile e manutenibile.
November 27, 2025 (5mo ago)
Programmazione Funzionale vs OOP: Un Confronto Moderno
Esplora la programmazione funzionale vs OOP per capire quale paradigma è migliore per il tuo team. Scopri come costruire software scalabile e manutenibile.
← Back to blog
Programmazione Funzionale vs OOP: Un Confronto Moderno
Sommario: Confronta la programmazione funzionale e l'OOP per scegliere il paradigma giusto in termini di scalabilità, manutenibilità e produttività del team.
Introduzione
La scelta tra programmazione funzionale (PF) e programmazione orientata agli oggetti (OOP) plasma il modo in cui il tuo team progetta, testa e mantiene il software. Questa guida espone le differenze fondamentali, i compromessi pratici e un approccio ibrido in modo che tu possa scegliere gli strumenti giusti per il tuo progetto e il tuo team.
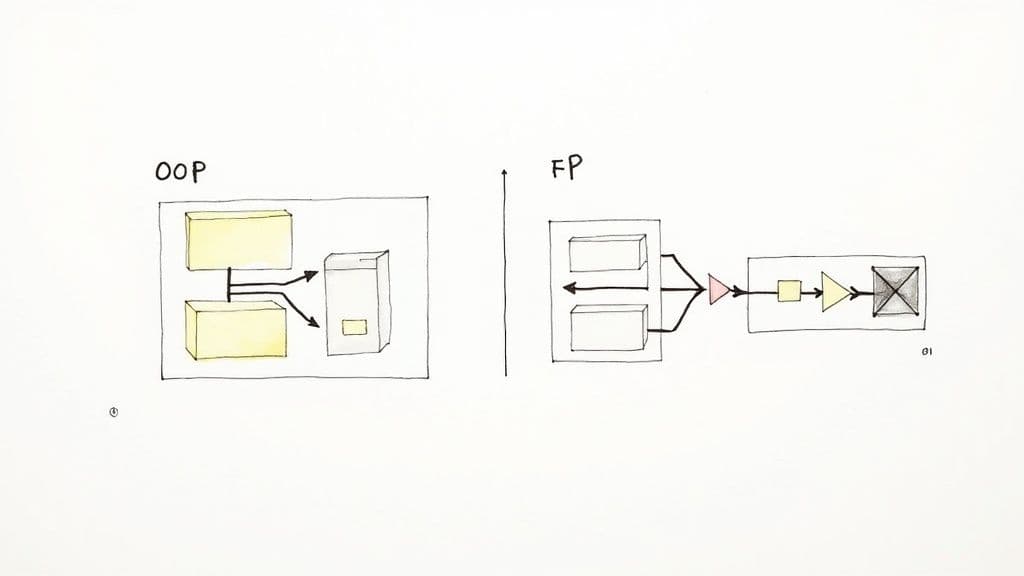
Decidere tra Programmazione Funzionale e OOP
Il paradigma che scegli influenza l'architettura, l'esperienza degli sviluppatori, i test e la manutenzione a lungo termine. In molte codebase moderne, un approccio ibrido — usare l'OOP per la struttura di alto livello e la PF per le trasformazioni dei dati — offre il meglio di entrambi i mondi.
- L'OOP funziona bene quando i sistemi sono modellati come entità che possiedono stato e comportamento, come applicazioni enterprise e GUI complesse.
- La PF eccelle per pipeline di dati, sistemi concorrenti e ovunque sia fondamentale codice prevedibile e privo di effetti collaterali.
Riferimento rapido: Con quale paradigma iniziare
| Scenario | Paradigma consigliato | Perché si adatta |
|---|---|---|
| GUI complessa con molti componenti interattivi e con stato | OOP | L'incapsulamento rende ogni componente responsabile del proprio stato. |
| Sistema enterprise su larga scala con dominio complesso | OOP | Naturale per modellare entità e relazioni di business. |
| Pipeline di elaborazione dati o ETL | PF | L'immutabilità e le funzioni pure rendono i flussi prevedibili e parallelizzabili. |
| Sistemi concorrenti in tempo reale (es. server di chat) | PF | Evitare stato mutabile condiviso riduce le condizioni di race. |
| Progetti che necessitano di una singola fonte di verità (es. alberi di stato) | PF | Gli alberi di stato immutabili semplificano riproducibilità e debugging. |
| Team con esperienza in linguaggi basati su classi | OOP | Curva di apprendimento più bassa e produttività iniziale più rapida. |
Tieni presente che questi sono punti di partenza, non regole rigide. Molti team strutturano i sistemi con OOP ai confini e PF per la logica interna.
Smontare i Principi Fondamentali di OOP e PF
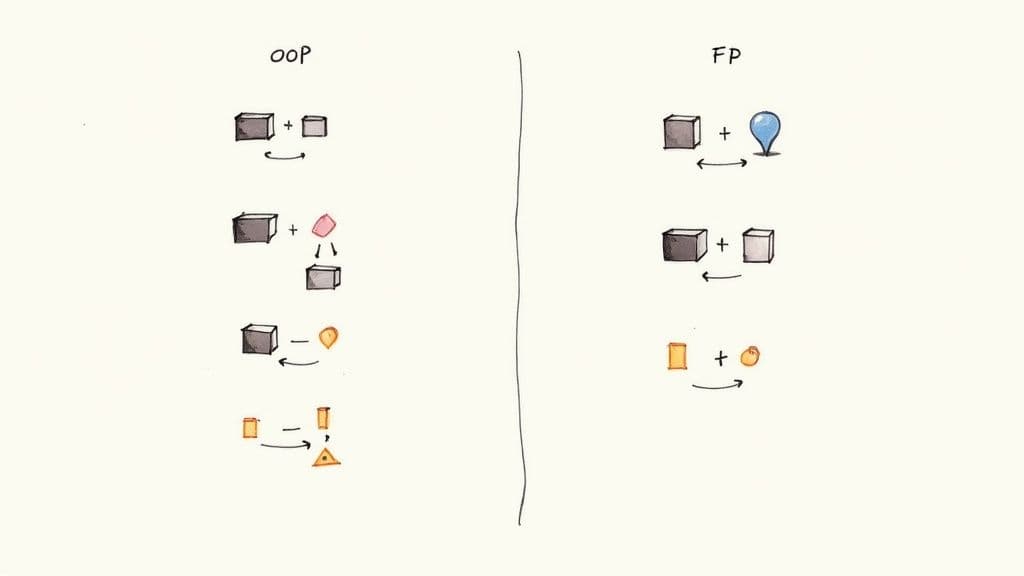
Il design orientato agli oggetti raggruppa dati e comportamento in oggetti, usando incapsulamento, ereditarietà e polimorfismo per gestire la complessità. Questo approccio rimane dominante in molti programmi educativi e codebase enterprise1.
La programmazione funzionale enfatizza funzioni pure, immutabilità e la minimizzazione degli effetti collaterali. Questo produce codice altamente testabile e prevedibile — prezioso in sistemi dove correttezza e riproducibilità contano di più.
Confronto Pratico: Come Gestiscono Stato e Dati
Al centro della differenza c'è come ogni paradigma affronta il cambiamento:
- L'OOP incapsula lo stato mutabile all'interno degli oggetti e lo aggiorna tramite metodi. Questo rispecchia la modellazione del mondo reale ma può complicare concorrenza e testing.
- La PF tratta i dati come immutabili e li trasforma tramite funzioni pure, creando nuovi valori invece di mutare quelli esistenti. Questo approccio a pipeline semplifica il ragionamento e il parallelismo.
L'adozione sta cambiando: mentre l'OOP rimane comune in molti progetti, l'uso della PF è in crescita, specialmente in domini ricchi di dati23.
Riepilogo affiancato
| Concetto | OOP | PF |
|---|---|---|
| Unità primaria | Oggetti che raggruppano stato e comportamento | Funzioni pure e dati immutabili |
| Stato | Mutabile e incapsulato | Immutabile; le trasformazioni producono nuovi dati |
| Flusso dei dati | Gli oggetti chiamano metodi e modificano stato interno | I dati fluiscono attraverso pipeline di funzioni |
| Concorrenza | Richiede sincronizzazione per lo stato condiviso | Più semplice grazie all'immutabilità e all'assenza di stato condiviso |
| Obiettivo principale | Modellare entità e interazioni del mondo reale | Descrivere trasformazioni dei dati in modo dichiarativo |
Quando Usare OOP vs PF
Scegli OOP quando il tuo dominio beneficia di modelli di entità che contengono stato e comportamento. Scegli PF per trasformazioni prevedibili, elaborazione concorrente e pipeline testabili. Molti team combinano entrambi: usando classi per l'architettura di alto livello e funzioni pure per la logica centrale.
Per esempio, diversi team fintech hanno riportato guadagni misurabili dopo aver adottato la PF per l'elaborazione dei dati — riduzioni nell'uso della memoria e batch di elaborazione più veloci nei carichi di produzione4.
Adottare un Approccio Ibrido
Una strada pragmatica è introdurre pattern funzionali in modo incrementale:
- Sostituire i loop imperativi con metodi dichiarativi sugli array come map, filter e reduce.
- Estrarre la logica core di business in funzioni pure, facili da testare e riutilizzare.
- Mantenere oggetti per l'orchestrazione di alto livello e i modelli di dominio, e usare la PF per le trasformazioni pesanti di dati.
Questo approccio ibrido migliora la manutenibilità senza un rischio elevato di riscrittura completa. Per i team focalizzati sulle pratiche di sviluppo, segui guide di clean code e documentazione interna per standardizzare i pattern nella codebase.
Domande Comuni (FAQ)
D1: Dobbiamo scegliere un solo paradigma?
A1: No. Molti team mescolano i paradigmi — OOP per l'architettura e PF per i dati e la logica core — così puoi bilanciare familiarità e prevedibilità.
D2: La PF è sempre più veloce o più efficiente in memoria?
A2: Non necessariamente. L'immutabilità della PF può aumentare le allocazioni, ma scelte attente delle strutture dati e ottimizzazioni del runtime spesso mitigano l'overhead. Le prestazioni dipendono dall'implementazione e dal carico di lavoro.
D3: Come iniziamo a spostarci verso la PF in una codebase OOP?
A3: Inizia estraendo funzioni pure per la logica core, sostituendo i loop con metodi dichiarativi sugli array e scrivendo test per unità piccole e isolate. Il refactoring incrementale riduce il rischio.
Ulteriori Letture e Risorse Interne
- Guida a clean coding e architettura: /guides/clean-coding-principles
- Case study su miglioramenti delle prestazioni: /case-studies/fintech-performance
- Pattern architetturali e design ibridi: /resources/architecture
1.
Project Euclid, “Object-Oriented Programming, Functional Programming, and R,” https://projecteuclid.org/journals/statistical-science/volume-29/issue-2/Object-Oriented-Programming-Functional-Programming-and-R/10.1214/13-STS452.pdf
2.
Scalac.io, “Functional Programming vs OOP,” https://scalac.io/blog/functional-programming-vs-oop/
3.
Tendenze di adozione nell'industria e sondaggi discussi in report della community; vedi panoramiche su https://scalac.io/blog/functional-programming-vs-oop/ per cifre aggregate.
4.
Case study su Dev.to e report della community sui cambi di paradigma: articolo di Ben, “OOP vs Functional Programming,” https://dev.to/ben/oop-vs-functional-programming-5ej4
🙋🏻♂️
L'AI scrive codice.Tu lo fai durare.
Nell'era dell'accelerazione AI, il codice pulito non è solo una buona pratica — è la differenza tra sistemi che si scalano e codebase che collassano sotto il loro stesso peso.