Esplora la storia di Coda Panic Software, perché è fallito e le lezioni per i team di sviluppo moderni. Scopri le alternative robustesse di oggi.
February 5, 2026 (2mo ago)
Che cos’era Coda Panic Software e cosa può insegnarci?
Esplora la storia di Coda Panic Software, perché è fallito e le lezioni per i team di sviluppo moderni. Scopri le alternative robustesse di oggi.
← Back to blog
Che cos’era Coda Panic Software e cosa può insegnarci?
Esplora la storia di Coda Panic Software, perché è fallito e le lezioni che offre ai team di sviluppo moderni. Scopri le alternative robuste di oggi.
Introduzione
Potresti aver visto l’espressione coda panic software e aver pensato si riferisse a un’app commerciale. Non è così. Il termine indica il file system distribuito Coda, un progetto di ricerca della Carnegie Mellon University che mirava a risolvere i guasti catastrofici di sincronizzazione per il lavoro offline. La sua storia mostra come il genio tecnico possa essere annientato dalla complessità, e offre ancora lezioni pratiche per i team che costruiscono sistemi resilienti oggi.1
Districare l’eredità di Coda Panic Software
Immagina che siano i primi anni ’90 e stai modificando un file condiviso con una rete inaffidabile. Ogni riconnessione è una scommessa: il file resterà intatto o il sistema andrà in crash? Coda è stato concepito per rendere il lavoro disconnesso fluido. È nato dalla ricerca accademica alla Carnegie Mellon e si è concentrato nel ridurre i fallimenti di sincronizzazione che potevano corrompere i dati o provocare crash a livello di sistema.1
Coda ha introdotto idee importanti—replicazione ottimistica, caching aggressivo lato client e replica lato server—per permettere agli utenti di lavorare localmente e riconciliare le modifiche in seguito. Quelle idee furono influenti, ma l’integrazione profonda col kernel del progetto e la complessità operativa crearono una barriera elevata all’adozione.
Il sito storico del progetto Coda è una fonte primaria utile per comprendere gli obiettivi originali e le scelte progettuali.1
La visione contro la realtà
Coda era tecnicamente sofisticato, ma la sua installazione e manutenzione spesso richiedevano modifiche invasive al kernel. Tale complessità ha creato una forma di debito tecnico: ottimi risultati accademici che non erano pratici per l’uso generale. Un sistema tecnicamente superiore può comunque fallire se ignora semplicità ed esperienza dello sviluppatore.
“Il genio tecnico conta poco se lo strumento non è accessibile.”
La storia di Coda è un esempio prudente: le migliori soluzioni bilanciano ambizione con usabilità e sicurezza operativa.
L’ascesa e la caduta di un’idea brillante
Nato come successore di Andrew File System (AFS), Coda mirava a permettere agli utenti di modificare file offline e riconciliare poi le modifiche usando la replicazione ottimistica e il caching lato client. Su carta risolveva un problema reale per utenti mobili e disconnessi.
Il problema della complessità debilitante
Il tallone d’Achille di Coda era la complessità. Richiedeva modifiche al kernel e conoscenze operative approfondite per essere installato e mantenuto, il che lo ha tenuto confinato ai laboratori di ricerca. Mentre il mondo si muoveva verso strumenti più semplici e facili da adottare, Coda rimaneva difficile da gestire ed evolvere.
Col tempo, le soluzioni industriali che privilegiavano facilità d’uso e affidabilità divennero dominanti. Le applicazioni moderne enfatizzano codice pulito, esperienza dello sviluppatore e strumenti che minimizzano il rischio operativo.
Dentro l’architettura di Coda e i suoi difetti fatali
L’architettura distribuita di Coda usava replica lato server e caching aggressivo lato client per fornire alta disponibilità e accesso offline. Ma la risoluzione dei conflitti e le interazioni a livello di kernel introdussero un pericoloso punto singolo di guasto: un conflitto irrisolvibile durante la sincronizzazione poteva innescare un kernel panic e far crashare l’intero sistema.
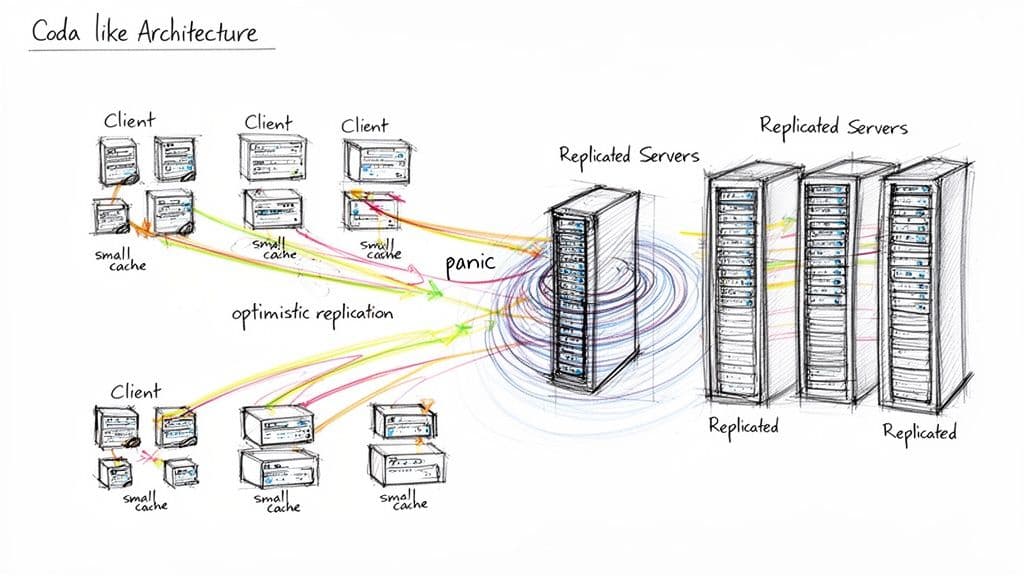
L’anatomia di un kernel panic
Lavorare offline e poi sincronizzare non dovrebbe mai mettere a rischio l’intero sistema operativo. L’approccio di Coda talvolta permetteva ai conflitti di sincronizzazione di eludere la gestione sicura a livello applicativo ed evolvere in fallimenti a livello di sistema. Questa fragilità nelle condizioni del mondo reale ne minava l’utilità.
Col tempo, progetti correlati nella comunità open-source hanno risolto molti bug a basso livello che affliggevano i file system distribuiti, dimostrando che i problemi sottostanti potevano essere corretti—se le soluzioni erano mantenibili e ampiamente adottate.2
Punti di forza vs debolezze architetturali di Coda
| Caratteristica | Forza (Visione) | Debolezza (Realtà) |
|---|---|---|
| Replicazione ottimistica | Permette lavoro offline e priorizza la produttività | Conflitti irrisolvibili potevano eludere salvaguardie e causare il fallimento del sistema |
| Caching lato client | Accesso locale rapido e resilienza ai problemi di rete | Cache corrotte e processi di recovery complessi rischiavano perdita di dati |
| Replica lato server | Alta disponibilità e ridondanza | Aggiungeva complessità alla logica di sincronizzazione e aumentava gli scenari di conflitto |
| Integrazione col kernel | Prestazioni e comportamento trasparente a livello OS | L’integrazione profonda significava che i bug potevano far crashare l’intero sistema |
L’integrazione profonda di Coda con il sistema operativo era al tempo stesso un vantaggio prestazionale e un rischio operativo inaccettabile per l’uso mainstream.
Echi moderni dei difetti di Coda
La lezione fondamentale è senza tempo: un singolo punto di failure non gestito può compromettere un intero sistema. Le pratiche ingegneristiche moderne—pattern di resilienza, contenimento dei guasti e architettura pulita—sono risposte dirette a questi tipi di rischi. Piattaforme aperte, ben mantenute e correzioni guidate dalla comunità hanno contribuito a ridurre l’incidenza dei guasti a basso livello che un tempo affondavano progetti come Coda.2
Scegliere gli strumenti nell’era post-Coda
La storia di Coda insegna ai responsabili engineering di scegliere strumenti che bilancino capacità ed esperienza dello sviluppatore. Gli editor e gli IDE odierni offrono flussi di lavoro che catturano la promessa originale di Coda—compatibilità offline, velocità e affidabilità—senza richiedere interventi sul kernel.
Per molti team, l’editor o l’IDE è un moltiplicatore di produttività quotidiana. Ecco tre scelte ampiamente usate:
Panic Nova: il successore dell’editor Coda
Panic Inc. (produttrice di Nova) non è correlata al file system Coda, sebbene l’editor precedente di Panic si chiamasse anch’esso Coda. Nova è un editor nativo per Mac noto per la velocità, un’interfaccia curata e una integrazione fluida con macOS. È particolarmente adatto ai team che lavorano sulle piattaforme Apple e cercano un ambiente senza distrazioni.4
Visual Studio Code: lo standard del settore
Visual Studio Code è gratuito, multipiattaforma e supportato da un enorme ecosistema di estensioni. Bilancia facilità d’uso e customizzabilità e si integra bene con gli strumenti AI moderni. Per molti team rappresenta il giusto mix di flessibilità e produttività.5
IDE JetBrains: l’opzione da potenza
I prodotti JetBrains (IntelliJ, WebStorm, ecc.) offrono profonda intelligence sul codice, refactoring avanzato e potenti strumenti di debug. Sono ideali per basi di codice grandi e complesse dove l’analisi automatizzata e il refactoring sicuro contano maggiormente, anche se possono richiedere più risorse.
Confronto degli editor moderni per team orientati al codice pulito
| Caratteristica | Panic Nova | Visual Studio Code | JetBrains (WebStorm/IntelliJ) |
|---|---|---|---|
| Prestazioni e sensazione | Velocità e reattività native su macOS | Buone prestazioni cross-platform; può rallentare con molte estensioni | Potente, può essere esoso di risorse |
| Affiancamento AI | Supporto alle estensioni in crescita | Integrazione di primo piano con strumenti AI | Forte intelligence di codice integrata |
| Refactoring e analisi | Funzionalità di base out-of-the-box; estendibile | Buoni strumenti e molte estensioni | Refactoring automatico leader nel settore |
| Ecosistema | Estensioni curate | Marketplace enorme | Ecosistema di plugin robusto |
Scegli l’editor che si adatta alla piattaforma, alla scala e al flusso di lavoro del tuo team. Lo strumento giusto potenzia gli sviluppatori invece di creare attrito.
Come evitare di costruire il tuo "panic software"
L’eredità di Coda è una guida pratica: evita fragilità nascoste, eccessiva complessità e debito tecnico incontrollato. Concentrati su tre pilastri ingegneristici per costruire sistemi resilienti:
Dai priorità alla semplicità e all’esperienza dello sviluppatore
Se l’onboarding richiede giorni, o i nuovi ingegneri non riescono a ottenere un ambiente stabile in poche ore, il tuo sistema ha un problema di attrito. Preferisci API chiare, overhead operativo minimo e cicli di feedback rapidi per gli sviluppatori.
Progetta per la resilienza
Progetta per il contenimento. I guasti dovrebbero essere isolati, registrati e recuperabili. Usa confini di errore chiari nei framework front-end e circuit breaker, retry e operazioni idempotenti nei sistemi back-end.
Progetta per l’evoluzione
Scrivi codice modulare e ben documentato usando pattern consolidati. Rendi le modifiche sicure ed economiche così che la codebase possa evolvere senza timori.

Domande comuni su Coda e lo sviluppo moderno
Panic Inc. (produttrice di Nova) è correlata al file system Coda?
No. Panic Inc. è una società separata il cui editor precedente si chiamava Coda. Il file system distribuito Coda della CMU è un progetto di ricerca indipendente senza collegamenti diretti ai prodotti di Panic.4
Qual è la lezione più grande per un CTO dalla storia di Coda?
La lezione più grande è che l’esperienza dello sviluppatore conta tanto quanto il design tecnico. Uno strumento affidabile e facile da usare che permette ai team di rilasciare con continuità è preferibile a un sistema tecnicamente elegante ma rischioso.
Come posso capire se la mia codebase ha tratti di “panic software”?
Cerca onboarding doloroso, fallimenti a effetto domino, ansia da deploy e parti della codebase che nessuno osa toccare. Questi sono segnali che un audit obiettivo e un refactor mirato potrebbero offrire valore significativo.
At Clean Code Guy, trasformiamo codebase fragili in asset stabili e scalabili. I nostri AI-Ready Refactors e Clean Code Audits aiutano a rimuovere i tratti di “panic software” così che i team possano rilasciare con fiducia.
Q&A — risposte rapide a preoccupazioni comuni
Q: Quali passi immediati fermano i fallimenti a cascata?
A: Aggiungi confini di errore chiari, aumenta l’osservabilità e isola i componenti così che i guasti non si propaghino.
Q: Come miglioro rapidamente l’onboarding degli sviluppatori?
A: Fornisci ambienti di sviluppo riproducibili, script di setup concisi e un dataset sandbox per validazioni iniziali.
Q: Quando dovrei chiamare aiuto esterno?
A: Se i deploy generano ansia o aree critiche sono praticamente off-limits, un audit può fornire un piano di remediazione prioritario.
1.
Carnegie Mellon University, “Coda Project,” https://www.cs.cmu.edu/~coda/.
2.
OpenAFS project, ChangeLog for 1.4.15 documenting fixes related to volume read/write panics, https://www.openafs.org/frameset/dl/openafs/1.4.15/ChangeLog.
3.
Dropbox website, company information and product history, https://www.dropbox.com/.
4.
Panic Inc., Nova editor and company history, https://nova.app/.
5.
Visual Studio Code, product overview and downloads, https://code.visualstudio.com/.
6.
JetBrains, product pages for IntelliJ IDEA and WebStorm, https://www.jetbrains.com/.
🙋🏻♂️
L'AI scrive codice.Tu lo fai durare.
Nell'era dell'accelerazione AI, il codice pulito non è solo una buona pratica — è la differenza tra sistemi che si scalano e codebase che collassano sotto il loro stesso peso.