Découvrez comment maîtriser les conventions de nommage en programmation conduit à un code plus propre et plus évolutif. Apprenez des règles pratiques, l'automatisation et des stratégies de déploiement.
February 4, 2026 (2mo ago)
Guide des conventions de nommage en programmation pour un code propre
Découvrez comment maîtriser les conventions de nommage en programmation conduit à un code plus propre et plus évolutif. Apprenez des règles pratiques, l'automatisation et des stratégies de déploiement.
← Back to blog
Conventions de nommage pour un code propre et évolutif
Découvrez comment maîtriser les conventions de nommage en programmation conduit à un code plus propre et plus évolutif. Apprenez des règles pratiques, l'automatisation et des stratégies de déploiement.
Introduction
Les conventions de nommage sont plus qu'un choix de style — ce sont un langage partagé qui rend le code lisible, maintenable et plus sûr à modifier. De bons noms réduisent la charge mentale, accélèrent l'intégration des nouveaux et améliorent l'automatisation, des linters aux assistants IA. Ce guide propose des règles pratiques pour TypeScript, React et Node, ainsi que des stratégies d'application et de déploiement pour ancrer les conventions.
Pourquoi les conventions de nommage sont la première défense de votre base de code
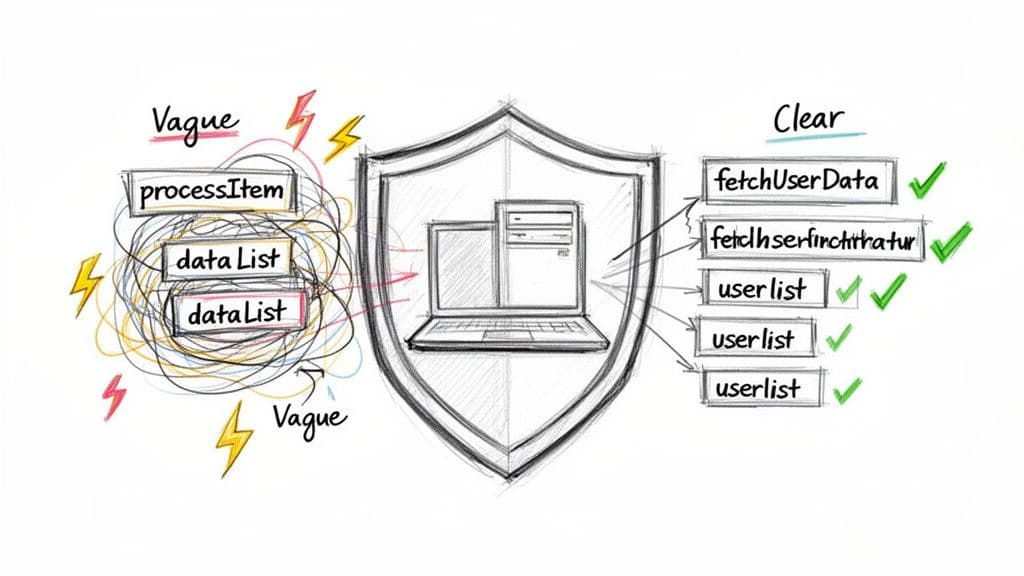
Le nommage ne relève pas de l'esthétique ; il s'agit de communication claire. Chaque variable, fonction et composant fait partie de l'histoire de votre appli. Des noms vagues ou incohérents obligent le lecteur à s'arrêter et à chercher le contexte, transformant de petites corrections en gouffres temporels.
Un seul nom de fonction peu clair peut provoquer des minutes ou des heures de débogage perdues. Quand cela se répète dans une équipe, la productivité chute et les incidents deviennent plus probables. Une base de code avec des noms clairs et cohérents devient effectivement « auto-documentée », réduisant le besoin de commentaires longs et rendant le système plus facile à parcourir.
Le coût réel d'un mauvais nommage
Considérez un backend Node.js avec une fonction appelée processItem() et un argument nommé dataList. Que fait-elle réellement ? Pour répondre, vous pourriez devoir lire l'implémentation, tracer les appelants ou lancer un débogueur. Ces détours s'accumulent et peuvent mener à de véritables échecs lorsque les hypothèses ne sont pas claires.
Un audit sur des projets en phase initiale a révélé une incohérence généralisée dans le nommage et des ralentissements mesurables dans l'intégration et le débogage, soulignant comment le nommage affecte la vélocité et la fiabilité des équipes.1
Statistique Canada souligne également comment des normes cohérentes réduisent les erreurs d'intégration dans les projets gouvernementaux, démontrant que le nommage et la normalisation comptent à grande échelle.2
Conventions de nommage et évolutivité des équipes
Le problème s'aggrave à mesure que les équipes grandissent. Un nommage incohérent rend le code plus difficile à comprendre pour les nouveaux arrivants et ralentit la collaboration. Adopter des conventions partagées tôt prévient la dette héritée et réduit les frictions lors de la montée en charge.
Styles de nommage courants en un coup d'œil
Ce référentiel rapide montre les styles de casse courants et où ils sont typiquement utilisés :
| Style de casse | Exemple | Cas d'utilisation principal |
|---|---|---|
| camelCase | let userName = "Alex"; | Variables et fonctions (JavaScript/TypeScript) |
| PascalCase | class UserProfile {} | Classes, interfaces, types, composants React |
| snake_case | const API_KEY = "..."; | Constantes ou langages comme Python |
| kebab-case | user-profile.css | Noms de classes CSS, noms de fichiers et URLs |
Comprendre quand utiliser chaque style construit un vocabulaire prévisible à l'échelle d'un projet.
Préparer votre code pour la collaboration avec l'IA
Les outils IA comme GitHub Copilot et Cursor fonctionnent mieux avec un code cohérent. Ils apprennent les motifs de votre base de code et les reproduisent dans leurs suggestions.
- Suggestions IA prévisibles : les booléens préfixés par
isouhasconduisent à une logique conditionnelle plus claire. - Génération de fonctions précise : des fonctions qui récupèrent des données nommées de manière cohérente
fetchSomethingaident l'IA à produire du code async correct. - Refactorings plus intelligents : des noms cohérents aident les outils à détecter les relations et à produire des changements plus sûrs.
En rendant les conventions de nommage explicites, vous améliorez la lisibilité humaine et faites de vos assistants IA des collaborateurs plus fiables.
Règles pratiques de nommage pour TypeScript, React et Node
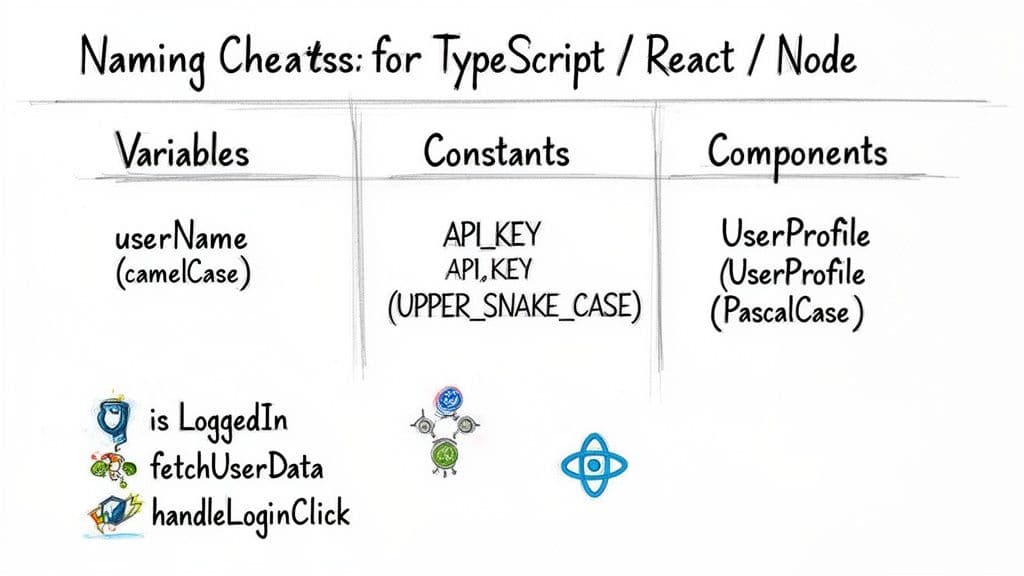
Ces règles sont éprouvées pour les stacks web modernes et réduisent la charge cognitive au sein de votre équipe.
Conventions de base JavaScript et TypeScript
-
Variables et fonctions : utilisez camelCase
- Bon :
let userProfile = {}; - Bon :
function calculateTotalPrice() {} - Mauvais :
let UserProfile = {};(ressemble à une classe)
- Bon :
-
Classes, interfaces, types : utilisez PascalCase
- Bon :
class AuthenticationService {} - Bon :
interface User { id: string }
- Bon :
-
Constantes véritables : utilisez UPPER_SNAKE_CASE
- Bon :
const API_BASE_URL = '...' - Bon :
const MAX_LOGIN_ATTEMPTS = 5;
- Bon :
Bien maîtriser ces bases rend les identifiants immédiatement reconnaissables.
Nommage sémantique pour la clarté
Utilisez des mots et préfixes qui signalent l'intention. Des distinctions claires entre variables et fonctions réduisent les bugs et les mauvaises interprétations. Les études et audits montrent que les équipes qui adoptent un nommage explicite réduisent les taux de bugs et améliorent la maintenabilité.3
Règles spécifiques à React
-
Composants et noms de fichiers : utilisez PascalCase
function UserProfile() { ... }→ fichierUserProfile.tsx
-
Handlers d'événements : préfixez par
handlefunction handleLoginClick() { ... }
-
Paires useState : suivez
[thing, setThing]const [isLoading, setIsLoading] = useState(false);
Nommage orienté action et descriptif
- Booléens : préfixez par
is,hasoucan(isModalOpen,hasUnsavedChanges) - Fonctions : nommez avec des verbes (
fetchUserData,validateInput,saveSettings)
Adoptez un nommage qui se lit comme de l'anglais courant — cela rend le code plus intuitif et réduit le besoin de commentaires.
Automatiser la cohérence pour appliquer les règles de nommage
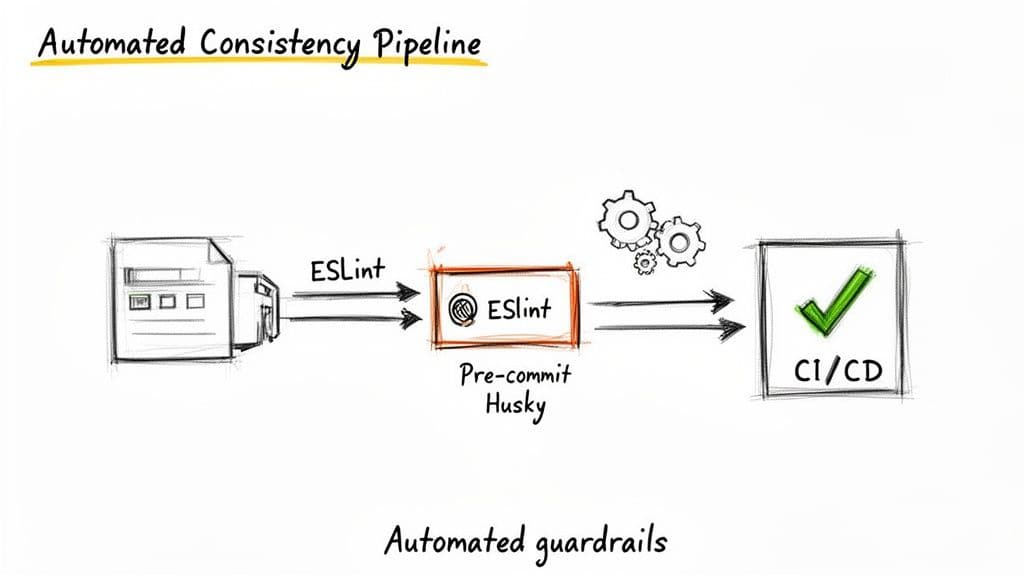
Définir des règles est la première étape ; l'automatisation les fait tenir. Se fier uniquement aux revues de code pour la cohérence du nommage gaspille le temps des relecteurs et laisse des angles morts.
ESLint : votre première ligne de défense
ESLint fournit des retours en temps réel dans les éditeurs et peut appliquer des règles de nommage via des règles personnalisées ou des plugins. Utilisez une configuration ESLint partagée afin que tout le monde reçoive les mêmes vérifications.
- Les corrections en temps réel empêchent les erreurs avant qu'elles ne soient committées.
- Les règles adaptées appliquent des conventions spécifiques à l'équipe (par ex., préfixes de booléens).
- Les configs partagées éliminent les débats de style et réduisent les frictions.
Hooks pré-commit avec Husky
Husky exécute des scripts au commit. Combiné à lint-staged, il empêche du code non conforme d'entrer dans le repo en lançant ESLint sur les fichiers en staging et en rejetant les commits qui échouent aux vérifications.
Linting en CI
Exécutez toujours le linter en CI comme porte finale. Le CI agit comme source de vérité objective et bloque les pull requests qui introduisent des violations de nommage ou d'autres erreurs de style.
Cette approche en trois couches — linting éditeur, hooks pré-commit et CI — applique les standards avec un minimum de surveillance manuelle.
Architecturer votre structure de fichiers et dossiers
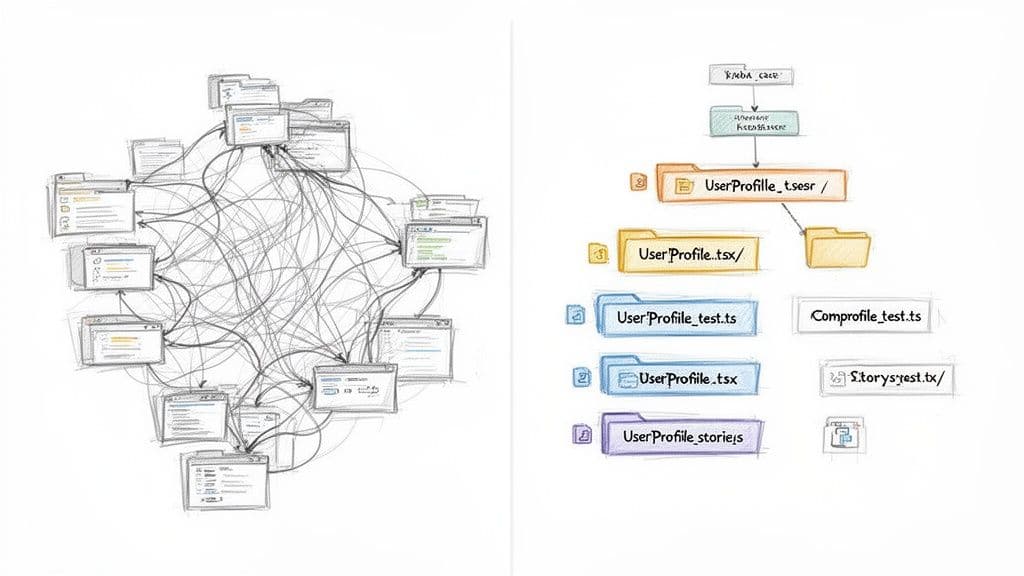
Les conventions de nommage s'étendent aux fichiers et répertoires. Une architecture prévisible aide les nouveaux développeurs à trouver rapidement le code et réduit la charge cognitive lors des modifications.
Structurer par fonctionnalité, pas par type
Organisez le code autour des fonctionnalités ou des domaines plutôt que par type de fichier. Colocalisez composants, services, hooks et tests d'une fonctionnalité dans le même répertoire. Par exemple, mettez tout ce qui concerne l'authentification dans /auth.
Cela rend les fonctionnalités autonomes et plus faciles à raisonner, tester ou retirer.
Règles essentielles de nommage de fichiers
- Répertoires : utilisez kebab-case (
user-profile,auth-service) - Composants React : PascalCase (
UserProfile.tsx) - Utilitaires et services : camelCase (
apiClient.ts,stringUtils.ts) - Utilisez des suffixes descriptifs (
.test.ts,.stories.tsx,.styles.ts)
Un système de fichiers cohérent réduit les conflits de merge et aide les équipes réparties à collaborer.
Comment déployer de nouvelles conventions dans une base de code existante
Un refactor complet et immédiat est risqué. Adoptez plutôt une approche incrémentale : laissez toujours le code un peu plus propre que vous ne l'avez trouvé.
Commencez par une conversation
Obtenez l'adhésion de l'équipe en expliquant les bénéfices mesurables : intégration plus rapide, moins de bugs et meilleure productivité des développeurs. Lancez un pilote sur un module unique pour démontrer les gains et créer de l'élan.
Documentez les règles
Mettez les conventions dans CONTRIBUTING.md ou le README du projet. Utilisez des exemples clairs montrant le bon et le mauvais. Expliquez brièvement la logique pour que les règles tiennent.
Laissez le linter faire le gros du travail
Configurez les outils pour appliquer les règles uniquement au code nouveau ou modifié : utilisez lint-staged, Husky et des vérifications CI limitées aux changements des PR. Cela évite de bloquer le travail sur de gros fichiers legacy tout en assurant que toutes les nouvelles modifications respectent la norme.
Mesurez le succès
Suivez des signaux tels que :
- Moins de commentaires sur le nommage dans les PR
- Cycles de revue plus rapides
- Meilleurs retours d'intégration des nouvelles recrues
Ces indicateurs montrent si vos conventions améliorent la vélocité de l'équipe et la clarté du code.
Questions courantes sur les conventions de nommage
Comment obtenir l'adhésion des développeurs seniors ?
Concentrez-vous sur les bénéfices au niveau de l'équipe plutôt que sur les préférences personnelles. Utilisez des données d'audits ou des refactors pilotes pour montrer des améliorations concrètes en lisibilité et temps de revue. Faites-en une décision possédée par l'équipe, pas un mandat imposé du sommet.
Quelle est la meilleure convention de nommage pour les endpoints d'API ?
Pour les API RESTful, utilisez des noms de ressources au pluriel et laissez les méthodes HTTP définir les actions. Exemple : GET /users, GET /users/{userId}, POST /users. Évitez les verbes dans les URLs pour garder les APIs prévisibles et indépendantes du langage.
Les fichiers de test doivent-ils avoir leurs propres conventions de nommage ?
Oui. Faites miroiter le nom du composant ou du module et ajoutez .test.ts ou .spec.ts. Gardez les tests à côté des fichiers qu'ils couvrent et écrivez des descriptions de test qui se lisent comme des phrases humaines.
Q&R rapide — Trois réponses concises
Q : Quelle est la règle de nommage la plus impactante pour commencer ?
A : Utilisez camelCase pour les variables/fonctions, PascalCase pour les types/composants, et UPPER_SNAKE_CASE pour les constantes véritables. Ces indices visuels seuls réduisent considérablement la confusion.
Q : Comment appliquer le nommage sans casser la build sur du code legacy ?
A : Configurez le linting pour s'exécuter uniquement sur les fichiers mis en staging et les fichiers modifiés (en utilisant lint-staged et des vérifications CI pour les PR). Cela applique les règles au nouveau travail tout en permettant d'améliorer le legacy de façon incrémentale.
Q : Comment les conventions de nommage aident-elles les outils IA comme Copilot ?
A : Des motifs cohérents enseignent à l'IA l'intention du projet, rendant les suggestions plus précises, les refactors plus sûrs et le code généré conforme aux conventions établies par l'équipe.
Chez Clean Code Guy, nous aidons les équipes à adopter des standards pratiques et réalisons des audits de bases de code et des refactors prêts pour l'IA afin de ramener structure et vélocité aux équipes d'ingénierie. En savoir plus sur https://cleancodeguy.com.
1.
Résultats d'audit et exemples d'équipe issus des revues de bases de code internes de Clean Code Guy montrant des incohérences de nommage courantes et leur impact : https://cleancodeguy.com
2.
Statistique Canada : exemple de standardisation des données et réduction des erreurs d'intégration : https://www150.statcan.gc.ca/n1/pub/12-001-x/2019001/article/00001-eng.htm
3.
CU Research Computing bonnes pratiques de codage et bénéfices observés d'un nommage plus clair : https://curc.readthedocs.io/en/latest/programming/coding-best-practices.html
4.
Enquête et analyse interne sur le nommage des fichiers, les conflits de merge et la maintenabilité à partir des retours de managers engineering et des audits de bases de code : https://cleancodeguy.com
🙋🏻♂️
L’IA écrit du code.Vous le faites durer.
À l’ère de l’accélération de l’IA, le code propre n’est pas seulement une bonne pratique — c’est la différence entre les systèmes qui évoluent et les codebases qui s’effondrent sous leur propre poids.