Choisir entre la programmation fonctionnelle (PF) et la programmation orientée objet (POO) façonne la manière dont votre équipe conçoit, teste et maintient le logiciel. Ce guide compare les principes, les cas d’usage et propose une approche hybride pour vous aider à prendre une décision pragmatique et mesurable.
November 27, 2025 (5mo ago) — last updated December 14, 2025 (4mo ago)
Programmation fonctionnelle vs POO : guide moderne
Comparez PF et POO pour choisir le paradigme adapté à votre projet : avantages, compromis, approche hybride et ressources pratiques.
← Back to blog
Programmation fonctionnelle vs OOP : une comparaison moderne
Résumé : Comparez la programmation fonctionnelle et la programmation orientée objet pour choisir le bon paradigme en termes d’évolutivité, de maintenabilité et de productivité d’équipe.
Introduction
Choisir entre la programmation fonctionnelle (PF) et la programmation orientée objet (POO) influence la façon dont votre équipe conçoit, teste et maintient le logiciel. Ce guide présente les différences fondamentales, les compromis pratiques et une approche hybride afin que vous puissiez sélectionner les bons outils pour votre projet et votre contexte d’équipe.
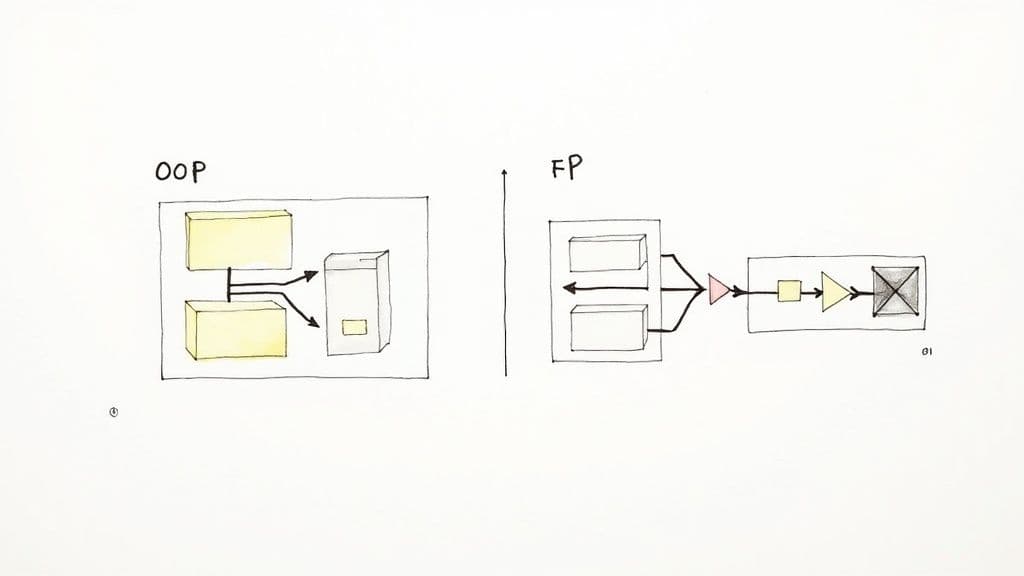
Comment décider entre PF et POO
Le paradigme choisi influence l’architecture, l’expérience développeur, les tests et la maintenance à long terme. Dans de nombreuses bases de code modernes, une approche hybride — POO pour la structure de haut niveau et PF pour les transformations de données — offre souvent un bon compromis1.
- La POO est adaptée aux systèmes modélisés comme des entités qui possèdent un état et un comportement, par exemple les applications d’entreprise et les interfaces graphiques complexes.
- La PF est particulièrement efficace pour les pipelines de données, les systèmes concurrents et partout où un code prévisible et sans effets de bord est critique. Les méthodes déclaratives (map, filter, reduce) améliorent la lisibilité et facilitent les tests unitaires.
Référence rapide : par quel paradigme commencer
| Scénario | Paradigme recommandé | Pourquoi il convient |
|---|---|---|
| Interface graphique complexe avec de nombreux composants interactifs et à état | POO | L’encapsulation rend chaque composant responsable de son propre état. |
| Système d’entreprise à grande échelle avec un domaine complexe | POO | Naturel pour modéliser des entités et des relations métier. |
| Pipeline de traitement de données ou ETL | PF | Immuabilité et fonctions pures rendent les flux prévisibles et parallélisables. |
| Systèmes concurrents en temps réel (par ex. serveur de chat) | PF | Éviter l’état mutable partagé réduit les conditions de concurrence. |
| Projets nécessitant une source unique de vérité (par ex. arbres d’état) | PF | Les arbres d’état immuables simplifient la reproductibilité et le débogage. |
| Équipes expérimentées avec des langages basés sur les classes | POO | Courbe d’apprentissage plus faible et productivité initiale plus rapide. |
Gardez à l’esprit qu’il s’agit de points de départ, pas de règles strictes. Beaucoup d’équipes structurent les frontières système en POO et la logique cœur en PF.
Principes clés de la POO et de la PF
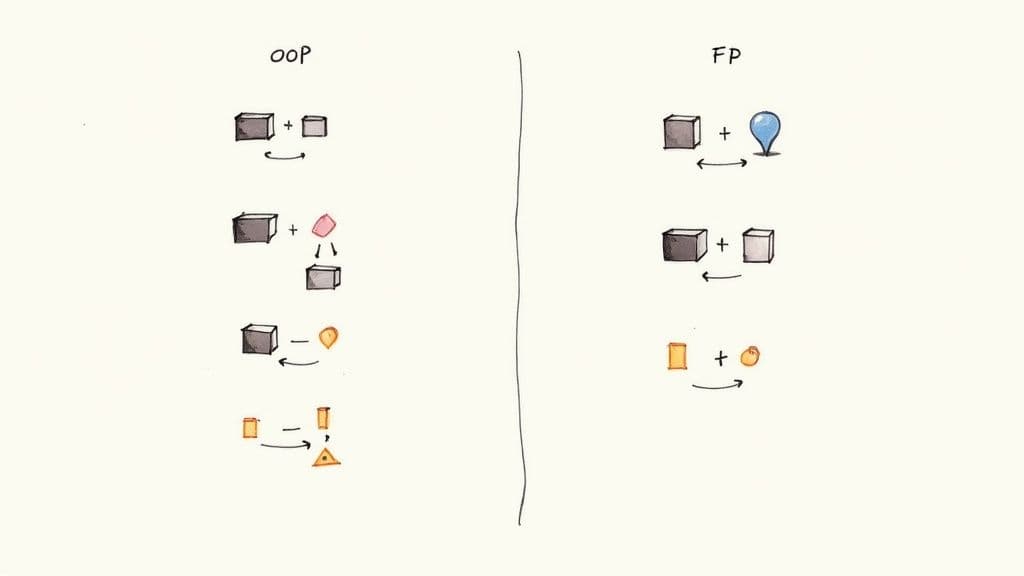
La POO regroupe les données et le comportement dans des objets, en s’appuyant sur l’encapsulation, l’héritage et le polymorphisme pour gérer la complexité. Cette approche reste dominante dans de nombreuses bases de code et environnements d’entreprise1.
La PF met l’accent sur les fonctions pures, l’immuabilité et la minimisation des effets de bord. Elle produit du code hautement testable et prévisible — précieux dans les systèmes où la reproductibilité et la fiabilité importent le plus. L’adoption des patterns fonctionnels a progressé ces dernières années, notamment dans les équipes traitant de gros volumes de données24.
Comment ils gèrent l’état et les données
Au cœur de la différence se trouve la gestion du changement :
- La POO encapsule l’état mutable dans des objets et le met à jour via des méthodes. Cela reflète souvent la modélisation du monde réel mais peut compliquer la concurrence et les tests.
- La PF considère les données comme immuables et les transforme via des fonctions pures, créant de nouvelles valeurs plutôt que de muter les existantes. Cette approche en pipeline simplifie le raisonnement et le parallélisme.
L’adoption évolue : bien que la POO reste courante, l’utilisation de PF et de patterns fonctionnels a augmenté dans les secteurs data-driven24.
Résumé côte à côte
| Concept | POO | PF |
|---|---|---|
| Unité principale | Objets regroupant état et comportement | Fonctions pures et données immuables |
| État | Mutable et encapsulé | Immuable ; transformations produisent de nouvelles données |
| Flux de données | Objets appellent des méthodes et modifient l’état interne | Données circulent dans des pipelines de fonctions |
| Concurrence | Nécessite synchronisation pour l’état partagé | Plus simple grâce à l’immuabilité |
| Objectif principal | Modéliser entités et interactions réelles | Décrire transformations de données de façon déclarative |
Quand utiliser la POO ou la PF
Choisissez la POO lorsque votre domaine bénéficie de modèles d’entités qui détiennent état et comportement. Choisissez la PF pour des transformations prévisibles, le traitement concurrent et des pipelines testables. Beaucoup d’équipes combinent les deux : classes pour l’architecture de haut niveau, fonctions pures pour la logique cœur.
Plusieurs équipes fintech ont rapporté des gains mesurables après l’adoption de patterns fonctionnels pour le traitement des données, notamment des réductions d’utilisation mémoire et des traitements batch plus rapides3.
Adopter une approche hybride (pratique)
Une voie pragmatique consiste à introduire des patterns fonctionnels progressivement :
- Remplacez les boucles impératives par des méthodes déclaratives comme map, filter et reduce.
- Extrayez la logique métier en fonctions pures faciles à tester et à réutiliser.
- Conservez des objets pour l’orchestration et les modèles de domaine, et utilisez la PF pour les transformations intensives de données.
Ce type de migration incrémentale améliore la maintenabilité sans risquer une réécriture complète. Pour standardiser les patterns, maintenez des guides internes et des exemples dans la documentation technique (voir les ressources ci-dessous).
FAQ
Doit-on choisir un seul paradigme ?
Non. Beaucoup d’équipes mélangent les paradigmes — POO pour l’architecture et PF pour la logique et les pipelines — afin d’équilibrer familiarité et prévisibilité.
La PF est-elle toujours plus rapide ou plus économe en mémoire ?
Pas nécessairement. L’immuabilité peut augmenter les allocations, mais des structures persistantes et des optimisations runtime réduisent souvent l’impact. Les performances dépendent de l’implémentation et de la charge de travail.
Comment commencer la PF dans une base orientée objet ?
Commencez par extraire des fonctions pures pour la logique cœur, remplacez les boucles par des méthodes déclaratives et écrivez des tests unitaires pour les petites unités isolées. Le refactoring incrémental réduit les risques.
Questions rapides (Q&R supplémentaires)
Q : Quel gain immédiat puis-je attendre en introduisant des patterns PF ? R : Meilleure testabilité et compréhension locale du code, réduction des effets de bord dans les transformations de données.
Q : La PF convient-elle aux petites équipes ? R : Oui, surtout si vous traitez des flux de données ou souhaitez réduire les bugs liés à l’état mutable. Commencez par des patterns simples.
Q : Quelle est la meilleure voie pour former l’équipe ? R : Sessions pratiques, revues de code axées sur patterns PF, et documentation interne avec exemples et anti-patterns.
Lectures complémentaires et ressources internes
- Guide sur le code propre et l’architecture : [/guides/clean-coding-principles]
- Études de cas sur les améliorations de performance : [/case-studies/fintech-performance]
- Patterns d’architecture et designs hybrides : [/resources/architecture]
1.
Project Euclid, “Object-Oriented Programming, Functional Programming, and R,” https://projecteuclid.org/journals/statistical-science/volume-29/issue-2/Object-Oriented-Programming-Functional-Programming-and-R/10.1214/13-STS452.pdf
2.
Scalac.io, “Functional Programming vs OOP,” https://scalac.io/blog/functional-programming-vs-oop/
3.
Ben, “OOP vs Functional Programming,” Dev.to, https://dev.to/ben/oop-vs-functional-programming-5ej4
4.
State of JS — résultats et tendances (utilisation de patterns fonctionnels et méthodes déclaratives), https://stateofjs.com/
5.
Stack Overflow Developer Survey — tendances et appréciation des langages, https://insights.stackoverflow.com/survey
🙋🏻♂️
L’IA écrit du code.Vous le faites durer.
À l’ère de l’accélération de l’IA, le code propre n’est pas seulement une bonne pratique — c’est la différence entre les systèmes qui évoluent et les codebases qui s’effondrent sous leur propre poids.