Explorez l'histoire du logiciel Coda Panic, pourquoi il a échoué, et les leçons qu'il offre aux équipes de développement modernes. Découvrez les alternatives robustes d'aujourd'hui.
February 5, 2026 (2mo ago)
Qu'était le logiciel Coda Panic et que peut-il nous enseigner ?
Explorez l'histoire du logiciel Coda Panic, pourquoi il a échoué, et les leçons qu'il offre aux équipes de développement modernes. Découvrez les alternatives robustes d'aujourd'hui.
← Back to blog
Qu'était le logiciel Coda Panic et que peut-il nous enseigner ?
Explorez l'histoire du logiciel Coda Panic, pourquoi il a échoué et les leçons qu'il offre aux équipes de développement modernes. Découvrez les alternatives robustes d'aujourd'hui.
Introduction
Vous avez peut-être vu l'expression coda panic software et supposé qu'elle désignait une application commerciale. Ce n'est pas le cas. Le terme renvoie au système de fichiers distribué Coda, un projet de recherche de la Carnegie Mellon University qui visait à résoudre les défaillances catastrophiques de synchronisation pour le travail hors ligne. Son histoire montre comment un génie technique peut être annulé par la complexité, et elle offre encore aujourd'hui des leçons pratiques pour les équipes qui construisent des systèmes résilients.1
Démêler l'héritage du logiciel Coda Panic
Imaginez que nous sommes au début des années 1990 et que vous modifiez un fichier partagé avec un réseau peu fiable. Chaque reconnexion est un pari : le fichier restera-t-il intact ou le système plantera-t-il ? Coda a été conçu pour rendre le travail déconnecté transparent. Il est né de la recherche académique à Carnegie Mellon et s'est concentré sur la réduction des échecs de synchronisation susceptibles de corrompre les données ou de déclencher des plantages au niveau du système.1
Coda a introduit des idées importantes — réplication optimiste, mise en cache agressive côté client et réplication côté serveur — pour permettre aux utilisateurs de travailler localement et de réconcilier les changements ultérieurement. Ces idées ont été influentes, mais l'intégration profonde dans le noyau et la complexité opérationnelle du projet ont créé une barrière élevée à l'adoption.
Le site historique du projet Coda est une source primaire utile pour comprendre les objectifs initiaux et les décisions de conception.1
La vision versus la réalité
Coda était techniquement sophistiqué, mais son installation et sa maintenance exigeaient souvent des modifications invasives du noyau. Cette complexité a créé une forme de dette technique : d'excellents résultats académiques qui n'étaient pas pratiques pour un usage général. Un système techniquement supérieur peut quand même échouer s'il ignore la simplicité et l'expérience développeur.
« Le génie technique signifie peu si l'outil n'est pas abordable. »
L'histoire de Coda est un exemple d'avertissement : les meilleures solutions équilibrent ambition, utilisabilité et sécurité opérationnelle.
L'ascension et la chute d'une idée brillante
Né comme successeur du Andrew File System (AFS), Coda visait à permettre aux utilisateurs d'éditer des fichiers hors ligne et de réconcilier les changements plus tard en utilisant la réplication optimiste et la mise en cache côté client. Sur le papier, il répondait à un vrai problème pour les utilisateurs mobiles et déconnectés.
Le problème de la complexité paralysante
Le talon d'Achille de Coda était la complexité. Il nécessitait des modifications du noyau et une connaissance opérationnelle approfondie pour être installé et maintenu, ce qui l'a confiné aux laboratoires de recherche. Alors que le monde se tournait vers des outils plus simples et plus faciles à adopter, Coda est resté difficile à exploiter et à faire évoluer.
Au fil du temps, des solutions industrielles qui privilégiaient la facilité d'utilisation et la fiabilité sont devenues dominantes. Les applications modernes mettent l'accent sur un code propre, l'expérience développeur et des outils qui minimisent le risque opérationnel.
À l'intérieur de l'architecture de Coda et ses défauts fatals
L'architecture distribuée de Coda utilisait la réplication côté serveur et une mise en cache agressive côté client pour fournir une haute disponibilité et un accès hors ligne. Mais la résolution des conflits et les interactions au niveau du noyau introduisaient un point de défaillance unique et dangereux : un conflit irrécupérable pendant la synchronisation pouvait déclencher un kernel panic et provoquer l'arrêt complet du système.
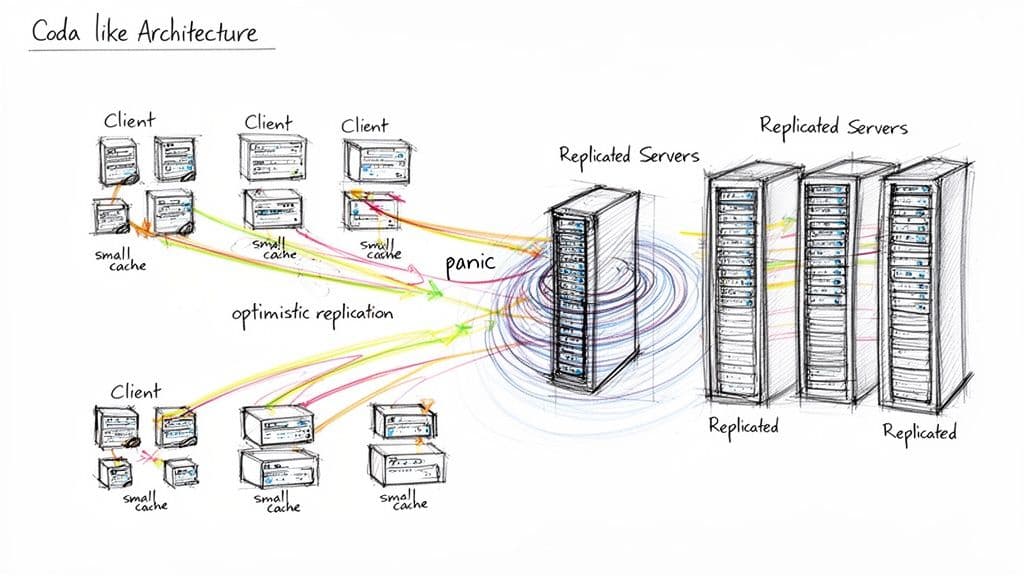
L'anatomie d'un kernel panic
Travailler hors ligne puis synchroniser ne devrait jamais mettre en risque le système d'exploitation entier. L'approche de Coda permettait parfois aux conflits de synchronisation d'échapper à une gestion sûre au niveau de l'application et d'escalader vers des défaillances au niveau système. Cette fragilité dans des conditions réelles a miné son utilité.
Au fil du temps, des projets apparentés dans la communauté open source ont corrigé de nombreux bogues bas niveau qui affectaient les systèmes de fichiers distribués, démontrant que les problèmes sous-jacents pouvaient être résolus — à condition que les solutions soient maintenables et largement adoptées.2
Forces architecturales vs faiblesses de Coda
| Feature | Strength (Vision) | Weakness (Reality) |
|---|---|---|
| Optimistic replication | Enables offline work and prioritizes productivity | Unresolvable conflicts could bypass safeguards and cause system failure |
| Client-side caching | Fast local access and resilience to network issues | Corrupted caches and complex recovery processes risked data loss |
| Server-side replication | High availability and redundancy | Added complexity to sync logic and increased conflict scenarios |
| Kernel integration | Performance and transparent OS-level behavior | Deep integration meant bugs could crash the whole system |
L'intégration profonde de Coda au niveau du système d'exploitation était à la fois un avantage de performance et un risque opérationnel inacceptable pour un usage grand public.
Échos modernes des défauts de Coda
La leçon essentielle est intemporelle : un seul point de défaillance non géré peut compromettre un système entier. Les pratiques d'ingénierie modernes — modèles de résilience, confinement des défaillances et architecture propre — répondent directement à ce type de risques. Des plates-formes ouvertes et bien entretenues ainsi que des correctifs communautaires ont contribué à réduire l'incidence des défaillances bas niveau qui coulaient autrefois des projets comme Coda.2
Choisir ses outils à l'ère post-Coda
L'histoire de Coda enseigne aux responsables techniques de choisir des outils qui équilibrent capacité et expérience développeur. Les éditeurs et IDE d'aujourd'hui offrent des workflows qui reprennent la promesse initiale de Coda — compatibles hors ligne, rapides et fiables — sans nécessiter de chirurgie du noyau.
Pour de nombreuses équipes, l'éditeur ou l'IDE est un multiplicateur de productivité quotidien. Voici trois choix largement utilisés :
Panic Nova : le successeur de l'éditeur Coda
Panic Inc. (éditeur de Nova) n'est pas lié au système de fichiers Coda, bien que l'éditeur antérieur de Panic ait également porté le nom Coda. Nova est un éditeur natif macOS connu pour sa rapidité, une interface soignée et une intégration fluide avec macOS. Il convient bien aux équipes engagées sur les plateformes Apple et cherchant un environnement sans distractions.4
Visual Studio Code : la référence de l'industrie
Visual Studio Code est gratuit, multiplateforme et soutenu par un énorme écosystème d'extensions. Il équilibre facilité d'utilisation et personnalisation et s'intègre bien aux outils d'IA modernes. Pour de nombreuses équipes, il trouve le bon équilibre entre flexibilité et productivité.5
IDE JetBrains : l'option puissante
Les produits JetBrains (IntelliJ, WebStorm, etc.) fournissent une intelligence de code approfondie, des refactorings avancés et de puissants outils de débogage. Ils sont idéaux pour les bases de code larges et complexes où l'analyse automatisée et le refactoring sûr sont essentiels, bien qu'ils puissent être plus gourmands en ressources.6
Comparaison des éditeurs modernes pour les équipes axées sur le code propre
| Feature | Panic Nova | Visual Studio Code | JetBrains (WebStorm/IntelliJ) |
|---|---|---|---|
| Performance & feel | Native macOS speed and responsiveness | Good cross-platform performance; can slow with many extensions | Powerful, can be resource-heavy |
| AI pairing | Growing extension support | First-class AI tool integration | Strong built-in code intelligence |
| Refactoring & analysis | Basic out of the box; extensible | Good tools and many extensions | Industry-leading automated refactoring |
| Ecosystem | Curated extensions | Massive marketplace | Robust plugin ecosystem |
Choisissez l'éditeur qui correspond à la plateforme, à l'échelle et aux besoins de workflow de votre équipe. L'outil adapté habilite les développeurs plutôt que de créer des frictions.
Comment éviter de construire votre propre « panic software »
L'héritage de Coda est un guide pratique : évitez la fragilité cachée, la complexité excessive et la dette technique incontrôlée. Concentrez-vous sur trois piliers d'ingénierie pour bâtir des systèmes résilients :
Prioriser la simplicité et l'expérience développeur
Si l'intégration prend des jours, ou si les nouveaux ingénieurs ne peuvent pas obtenir un environnement stable en quelques heures, votre système a un problème de friction. Privilégiez des API claires, une surcharge opérationnelle minimale et des boucles de rétroaction développeur rapides.
Concevoir pour la résilience
Concevez pour le confinement. Les défaillances doivent être isolées, consignées et récupérables. Utilisez des frontières d'erreur claires dans les frameworks front-end et des coupe-circuits, des tentatives de nouvelle exécution et des opérations idempotentes dans les systèmes back-end.
Concevoir pour l'évolution
Écrivez du code modulaire et bien documenté en utilisant des modèles établis. Rendez le changement sûr et peu coûteux afin que la base de code puisse évoluer sans crainte.

Questions fréquentes sur Coda et le développement moderne
Panic Inc. (éditeurs de Nova) sont-ils liés au système de fichiers Coda ?
Non. Panic Inc. est une entreprise distincte dont l'éditeur antérieur s'appelait Coda. Le système de fichiers distribué Coda de la CMU est un projet de recherche indépendant sans lien direct avec les produits de Panic.4
Quelle est la plus grande leçon pour un CTO de l'histoire de Coda ?
La plus grande leçon est que l'expérience développeur compte autant que la conception technique. Un outil fiable et facile à utiliser qui permet aux équipes de livrer de manière fiable est préférable à un système techniquement élégant mais risqué.
Comment savoir si ma base de code présente des traits de « panic software » ?
Recherchez une intégration pénible, des défaillances en chaîne, la crainte des déploiements et des parties de la base de code que personne n'ose toucher. Ce sont des signes qu'un audit objectif et un refactoring ciblé pourraient apporter une valeur majeure.
Chez Clean Code Guy, nous transformons des bases de code fragiles en actifs stables et évolutifs. Nos refactorisations prêtes pour l'IA et nos audits de code propre aident à éliminer les traits de « panic software » afin que les équipes puissent livrer en toute confiance.
Q&R — réponses rapides aux préoccupations courantes
Q : Quelles mesures immédiates arrêtent les défaillances en cascade ?
R : Ajoutez des frontières d'erreur claires, augmentez l'observabilité et isolez les composants pour que les défaillances ne se propagent pas.
Q : Comment améliorer rapidement l'intégration des développeurs ?
R : Fournissez des environnements de développement reproductibles, des scripts d'installation concis et un jeu de données sandbox pour une validation précoce.
Q : Quand devrais-je faire appel à une aide extérieure ?
R : Si les déploiements génèrent de l'anxiété ou si des zones critiques sont effectivement interdites d'accès, un audit peut fournir un plan de remédiation priorisé.
1.
Carnegie Mellon University, “Coda Project,” https://www.cs.cmu.edu/~coda/.
2.
OpenAFS project, ChangeLog for 1.4.15 documenting fixes related to volume read/write panics, https://www.openafs.org/frameset/dl/openafs/1.4.15/ChangeLog.
3.
Dropbox website, company information and product history, https://www.dropbox.com/.
4.
Panic Inc., Nova editor and company history, https://nova.app/.
5.
Visual Studio Code, product overview and downloads, https://code.visualstudio.com/.
6.
JetBrains, product pages for IntelliJ IDEA and WebStorm, https://www.jetbrains.com/.
🙋🏻♂️
L’IA écrit du code.Vous le faites durer.
À l’ère de l’accélération de l’IA, le code propre n’est pas seulement une bonne pratique — c’est la différence entre les systèmes qui évoluent et les codebases qui s’effondrent sous leur propre poids.