Descubre cómo dominar el hashmap en Ruby (Hash) para un código más limpio, rápido y escalable. Un análisis profundo de internals, rendimiento y buenas prácticas.
January 30, 2026 (2mo ago)
Dominar Hashmap en Ruby para un código limpio y escalable
Descubre cómo dominar el hashmap en Ruby (Hash) para un código más limpio, rápido y escalable. Un análisis profundo de internals, rendimiento y buenas prácticas.
← Back to blog
If you're familiar with the term hashmap in Ruby, you're really talking about Ruby's built-in Hash class. This powerful key-value store acts like a digital filing cabinet: every piece of data gets a unique label so you can find it again almost instantly.
Por qué dominar el Hash de Ruby cambia la forma en que programas
En su núcleo, un Hash de Ruby es una colección de claves únicas y sus valores. Piénsalo como un diccionario: buscas una palabra (la clave) para encontrar su definición (el valor). Los Hashes se usan en todas partes — desde los datos de sesión en aplicaciones web hasta la configuración — y destacan por operaciones rápidas, casi en tiempo constante, para inserciones y búsquedas1.
Dominar los Hashes es más que aprender la sintaxis. Significa adoptar un estilo de codificación más limpio y directo. En lugar de largas cadenas de if/else, a menudo puedes reemplazar la lógica con una simple búsqueda por clave. Eso conduce a una menor complejidad, mejor legibilidad y mantenimiento más sencillo.
Esta guía recorre cómo funciona el Hash de Ruby, usos idiomáticos y trampas comunes, recetas prácticas, alternativas cuando un Hash no es la mejor opción y patrones de refactorización que puedes aplicar hoy.
Cómo funciona un Hash de Ruby por dentro
Un Hash de Ruby es una implementación optimizada en C de una tabla hash. Cuando añades un par clave-valor, Ruby pasa la clave por una función hash para calcular un código hash. Ese código se mapea a un índice de cubeta en un arreglo interno, permitiendo que Ruby salte directamente a la ranura correcta en lugar de escanear los elementos uno por uno1.
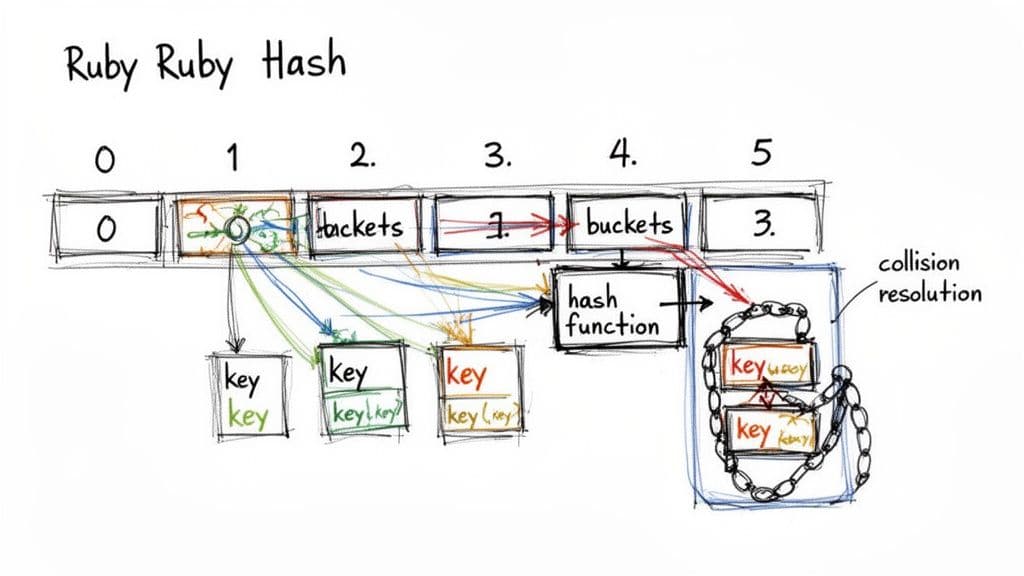
Función hash, cubetas y colisiones
La función hash reduce cualquier clave a un código numérico, que luego se convierte en un índice de cubeta. Las colisiones—cuando dos claves se mapean al mismo índice—son normales. Ruby almacena múltiples entradas por cubeta y escanea la pequeña lista cuando es necesario. Las optimizaciones recientes de Ruby mantienen ese escaneo pequeño y rápido.
Ruby 2.4 introdujo cambios internos importantes que mejoraron el rendimiento del hash al mejorar la localidad de datos y el comportamiento de redimensionamiento; esos cambios ofrecieron mejoras de velocidad sustanciales en cargas de trabajo comunes2.
Uso idiomático de Hash y trampas comunes
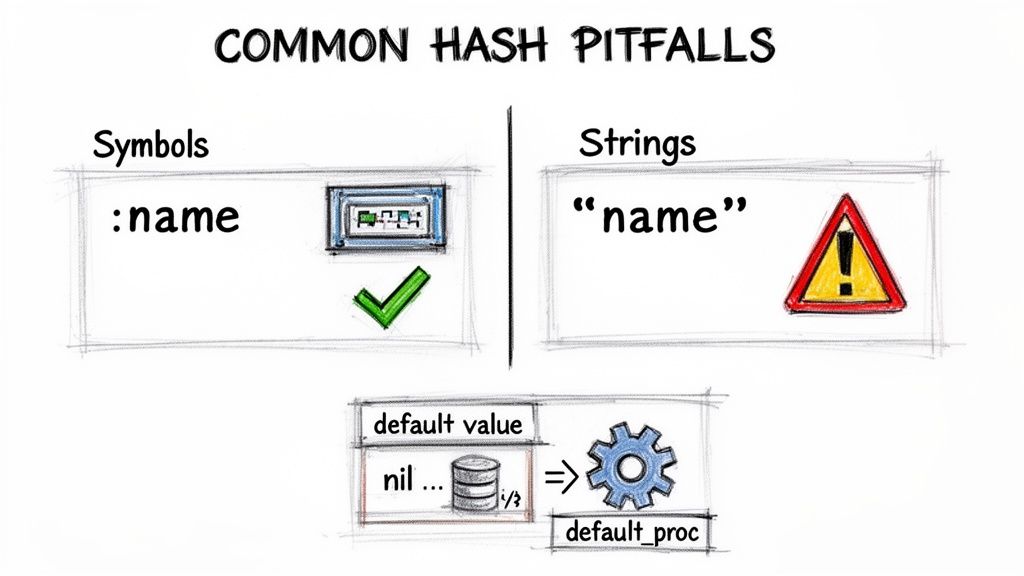
Conocer la teoría es útil, pero hacer que los Hashes funcionen bien en producción significa evitar errores sutiles y escribir código predecible.
Símbolos vs cadenas como claves
Los Símbolos y las Cadenas pueden parecer similares, pero se comportan de forma diferente. Un Símbolo es inmutable y se reutiliza entre usos, mientras que una Cadena crea un nuevo objeto cada vez. Por lo general, los Símbolos son más rápidos y más eficientes en memoria para claves, porque las comparaciones pueden hacerse por identidad de objeto en lugar de comparar carácter por carácter3.
Un error común es esperar una clave de Símbolo cuando los datos usan claves de Cadena (por ejemplo, parámetros web entrantes). Usa convenciones consistentes—convierte las claves entrantes con symbolize_keys o stringify_keys—para evitar este desajuste.
Valores por defecto y procs por defecto
Acceder a una clave inexistente devuelve nil, lo que puede causar un NoMethodError cuando llamas métodos sobre él. Usa un valor por defecto para evitar sorpresas:
# Safe default
fruit_counts = Hash.new(0)
fruit_counts["apple"] = 5
fruit_counts["orange"] # => 0
Para comportamientos más avanzados, un default proc te permite calcular o inicializar valores de forma perezosa.
merge vs merge!
merge devuelve un nuevo Hash y preserva el original. merge! muta in situ. Prefiere métodos no destructivos cuando quieras evitar efectos secundarios y mantener el flujo de datos predecible.
Freeze para inmutabilidad
Para constantes y configuraciones que no deben cambiar, llama a .freeze para evitar mutaciones accidentales:
CONFIG = { api_key: "abc-123", timeout: 5000 }.freeze
# CONFIG[:timeout] = 3000 # raises FrozenError
Recetario práctico de Hash en Ruby
Esta sección es una colección de recetas para tareas comunes.
Iteración y transformación
Usa each para iterar y select, reject, map, y to_h para filtrar y transformar de forma limpia:
user_permissions = { admin: true, editor: true, viewer: false }
active_roles = user_permissions.select { |role, has_access| has_access }
role_descriptions = user_permissions.map { |role, has_access| [role, "Can perform #{role} actions: #{has_access}"] }.to_h
Navegar de forma segura datos anidados con dig
dig evita NoMethodError al recorrer hashes anidados:
api_response = { user: { profile: { name: "Alice" } } }
email = api_response.dig(:user, :profile, :email) # => nil
name = api_response.dig(:user, :profile, :name) # => "Alice"
Limpiar y transformar claves/valores
compact, transform_keys, y transform_values hacen que remodelar y sanear datos sea conciso y legible:
messy_data = { "firstName" => "bob", "lastName" => "smith", "age" => 30 }
clean_data = messy_data
.transform_keys(&:to_sym)
.transform_values { |v| v.is_a?(String) ? v.capitalize : v }
# => { firstName: "Bob", lastName: "Smith", age: 30 }
Elegir la herramienta adecuada
Un Hash es flexible, pero no siempre es la mejor opción. Para esquemas fijos usa Struct; para notación punto con claves impredecibles usa OpenStruct (pero ten en cuenta el coste de rendimiento); para comprobaciones de unicidad usa Set—que está optimizado para pruebas de pertenencia y se construye sobre las estructuras núcleo de Ruby4.
Cuando eliges la estructura correcta, tu código se vuelve más rápido, claro y más fácil de mantener.
Comparación rápida
| Structure | Best for | Advantage | Consideration |
|---|---|---|---|
| Hash | Dynamic key-value data | Ultimate flexibility | More memory; potential key typos |
| Struct | Small, fixed attribute sets | Memory efficient; method access | Inflexible |
| OpenStruct | Prototyping, unpredictable keys | Dot-notation convenience | Slower; high memory |
| Set | Fast uniqueness checks | O(1) membership tests | No associated values |
Refactorizando con patrones de Hash
Usa Hashes para reemplazar largas cadenas de if/elsif o case moviendo los datos a una tabla de búsqueda. Eso separa los datos de la lógica y hace que añadir nuevos casos sea tan fácil como añadir una clave.
ENDPOINTS = {
development: "http://dev.api.example.com",
staging: "http://staging.api.example.com",
production: "https://api.example.com"
}.freeze
def get_api_endpoint(environment)
ENDPOINTS.fetch(environment, "http://localhost:3000")
end
Los Hashes de opciones también simplifican las firmas de método al agrupar parámetros opcionales en un único argumento extensible.
Preguntas frecuentes
¿Es un Hash de Ruby lo mismo que un hashmap?
Sí. Un hashmap es el término genérico de ciencias de la computación; en Ruby la clase se llama Hash e implementa una tabla hash con las características de complejidad temporal típicas de la estructura de datos1.
¿Qué error común debo evitar con los Hashes?
El error más frecuente es mezclar claves de Símbolo y Cadena. Establece y aplica una convención—típicamente Símbolos para claves internas—y normaliza la entrada externa temprano.
¿Cómo afecta el uso de Hash al rendimiento en Rails?
Los Hashes están en todas partes en Rails: params, datos de sesión y manejo de JSON. La creación ineficiente de Hashes y las operaciones pesadas repetidas pueden causar aumento de memoria y ralentizar las solicitudes. Perfiliza los puntos calientes y prefiere patrones in situ o perezosos cuando sea apropiado.
Preguntas rápidas — Preguntas comunes de desarrolladores
Q: ¿Cómo evito errores nil al acceder a claves anidadas?
A: Usa dig o proporciona valores por defecto seguros con Hash.new(default) o un default proc.
Q: ¿Cuándo debo cambiar de Hash a Struct o Set?
A: Usa Struct cuando los campos sean fijos y conocidos; usa Set cuando solo necesites unicidad y comprobaciones de pertenencia rápidas.
Q: ¿Cómo puedo fusionar configuraciones de múltiples fuentes de forma segura?
A: Prefiere merge no destructivo y congela la configuración final. Si necesitas actualizaciones in situ, usa merge! con precaución y documenta los efectos secundarios.
En Clean Code Guy, nuestra misión es ayudar a los equipos a convertir bases de código complicadas en activos fáciles de mantener y escalar. Profundizamos en principios como estos para ayudarte a entregar mejor software, más rápido. Descubre cómo podemos ayudarte a construir una aplicación resiliente y lista para IA en cleancodeguy.com.
1.
Wikipedia, "Tabla hash." https://en.wikipedia.org/wiki/Hash_table
2.
Ruby Issue Tracker, "Mejora del Hash (potencia de dos, localidad de datos)". https://bugs.ruby-lang.org/issues/12142
3.
Ruby Guides, "Símbolos en Ruby". https://www.rubyguides.com/2019/03/ruby-symbols/
4.
Documentación de la Biblioteca Estándar de Ruby, Set. https://ruby-doc.org/stdlib-2.7.0/libdoc/set/rdoc/Set.html
🙋🏻♂️
La IA escribe código.Tú lo haces durar.
En la era de la aceleración de la IA, el código limpio no es solo una buena práctica — es la diferencia entre sistemas que escalan y bases de código que colapsan bajo su propio peso.