Erkunde funktionale Programmierung vs OOP, um zu verstehen, welches Paradigma am besten für dein Team ist. Erfahre, wie man skalierbare und wartbare Software erstellt.
November 27, 2025 (5mo ago)
Funktionale Programmierung vs OOP: Ein moderner Vergleich
Erkunde funktionale Programmierung vs OOP, um zu verstehen, welches Paradigma am besten für dein Team ist. Erfahre, wie man skalierbare und wartbare Software erstellt.
← Back to blog
Funktionale Programmierung vs OOP: Ein moderner Vergleich
Zusammenfassung: Vergleiche funktionale Programmierung und OOP, um das richtige Paradigma für Skalierbarkeit, Wartbarkeit und Teamproduktivität auszuwählen.
Einführung
Die Entscheidung zwischen funktionaler Programmierung (FP) und objektorientierter Programmierung (OOP) prägt, wie dein Team Software entwirft, testet und wartet. Dieser Leitfaden stellt die Kernunterschiede, praktische Kompromisse und einen hybriden Ansatz dar, damit du die richtigen Werkzeuge für dein Projekt und dein Team auswählen kannst.
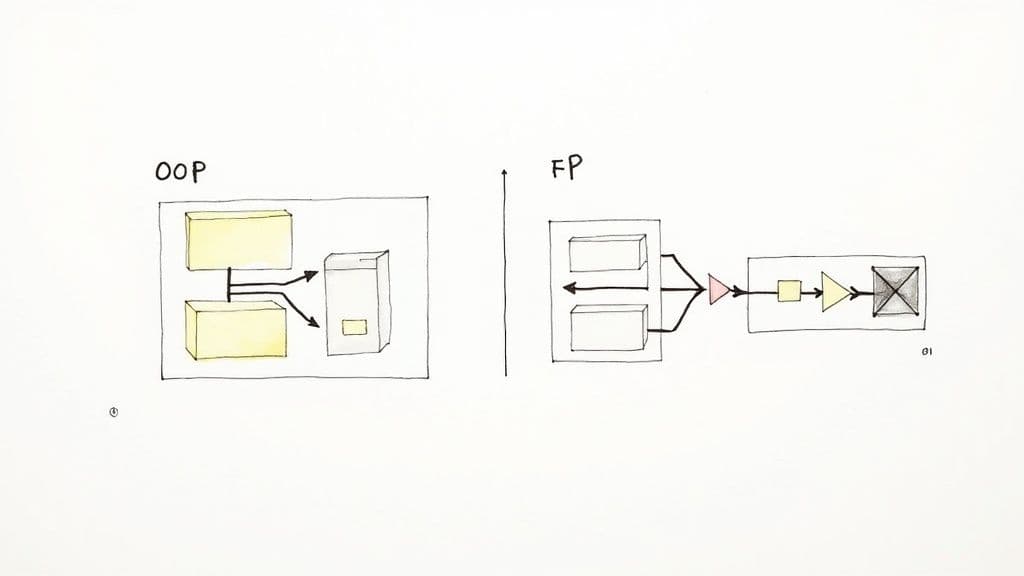
Entscheidung zwischen funktionaler Programmierung und OOP
Das gewählte Paradigma beeinflusst Architektur, Entwicklererfahrung, Tests und langfristige Wartung. In vielen modernen Codebasen bietet ein hybrider Ansatz – OOP für die grobe Struktur und FP für Datenumwandlungen – das Beste aus beiden Welten.
- OOP funktioniert gut, wenn Systeme als Entitäten modelliert werden, die Zustand und Verhalten besitzen, z. B. Unternehmensanwendungen und komplexe GUIs.
- FP glänzt bei Datenpipelines, nebenläufigen Systemen und überall dort, wo vorhersehbarer, nebenwirkungsfreier Code kritisch ist.
Kurzübersicht: Mit welchem Paradigma anfangen
| Scenario | Recommended Paradigm | Why It Fits |
|---|---|---|
| Complex GUI with many interactive stateful components | OOP | Encapsulation makes each component responsible for its own state. |
| Large-scale enterprise system with a complex domain | OOP | Natural for modelling business entities and relationships. |
| Data processing pipeline or ETL | FP | Immutability and pure functions make flows predictable and parallelizable. |
| Real-time concurrent systems (e.g., chat server) | FP | Avoiding shared mutable state reduces race conditions. |
| Projects that need a single source of truth (e.g., state trees) | FP | Immutable state trees simplify reproducibility and debugging. |
| Teams experienced with class-based languages | OOP | Lower learning curve and faster initial productivity. |
Beachte, dass dies Ausgangspunkte und keine starren Regeln sind. Viele Teams strukturieren Systeme mit OOP an den Grenzen und FP für die interne Logik.
Zerlegung der Kernprinzipien von OOP und FP
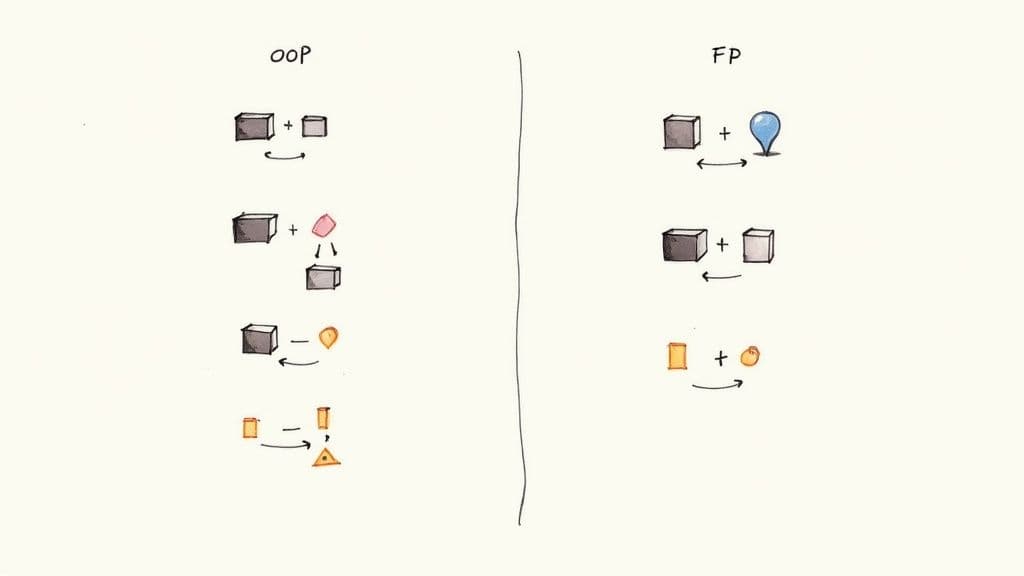
Objektorientiertes Design bündelt Daten und Verhalten in Objekten und nutzt Kapselung, Vererbung und Polymorphie, um Komplexität zu bewältigen. Dieser Ansatz bleibt in vielen Ausbildungen und Unternehmenscodebasen dominant1.
Funktionale Programmierung betont reine Funktionen, Unveränderlichkeit und die Minimierung von Nebenwirkungen. Das ergibt sehr testbaren, vorhersehbaren Code — wertvoll in Systemen, in denen Korrektheit und Reproduzierbarkeit am wichtigsten sind.
Praktischer Vergleich: Wie sie Zustand und Daten handhaben
Im Kern unterscheidet sich, wie jedes Paradigma mit Änderungen umgeht:
- OOP kapselt veränderlichen Zustand in Objekten und aktualisiert ihn über Methoden. Das spiegelt die Modellierung der realen Welt wider, kann aber Nebenläufigkeit und Tests verkomplizieren.
- FP behandelt Daten als unveränderlich und transformiert sie über reine Funktionen, wobei neue Werte erzeugt werden, anstatt bestehende zu verändern. Dieser Pipeline-Ansatz vereinfacht das Denken und Parallelisieren.
Die Adoption verschiebt sich: Während OOP in vielen Projekten weiterhin verbreitet ist, wächst die Nutzung von FP, besonders in datenreichen Domänen23.
Gegenüberstellung (Kurzfassung)
| Concept | OOP | FP |
|---|---|---|
| Primary Unit | Objects that bundle state and behavior | Pure functions and immutable data |
| State | Mutable and encapsulated | Immutable; transformations produce new data |
| Data Flow | Objects call methods and change internal state | Data flows through function pipelines |
| Concurrency | Requires synchronization for shared state | Easier due to immutability and no shared state |
| Core Goal | Model real-world entities and interactions | Describe data transformations declaratively |
Wann OOP vs FP verwenden
Wähle OOP, wenn deine Domäne von Entitätsmodellen profitiert, die Zustand und Verhalten halten. Wähle FP für vorhersehbare Transformationen, nebenläufige Verarbeitung und testbare Pipelines. Viele Teams kombinieren beides: Klassen für die Architektur auf hoher Ebene und reine Funktionen für die Kernlogik.
Beispielsweise berichteten mehrere FinTech-Teams von messbaren Verbesserungen nach der Einführung von FP für die Datenverarbeitung — Reduzierungen im Speicherverbrauch und schnellere Batch-Verarbeitung in Produktions-Workloads4.
Einführung eines hybriden Ansatzes
Ein pragmatischer Weg ist, funktionale Muster schrittweise einzuführen:
- Ersetze imperative Schleifen durch deklarative Array-Methoden wie map, filter und reduce.
- Extrahiere Kernlogik in reine Funktionen, die leicht zu testen und wiederzuverwenden sind.
- Behalte Objekte für die übergeordnete Orchestrierung und Domänenmodelle und nutze FP für datenintensive Transformationen.
Dieser hybride Ansatz verbessert die Wartbarkeit ohne riskante komplette Neuentwicklung. Für Teams, die sich auf Entwicklerpraktiken konzentrieren, befolge Clean-Code-Richtlinien und interne Dokumente, um Muster im Codebestand zu standardisieren.
Häufige Fragen (FAQ)
F1: Müssen wir uns auf nur ein Paradigma festlegen?
A1: Nein. Viele Teams mischen Paradigmen — OOP für Architektur und FP für Daten und Kernlogik — sodass du Vertrautheit und Vorhersehbarkeit ausbalancieren kannst.
F2: Ist FP immer schneller oder speichereffizienter?
A2: Nicht zwingend. FP‑Unveränderlichkeit kann mehr Allokationen verursachen, aber durchdachte Datenstrukturen und Laufzeitoptimierungen mindern oft den Overhead. Die Performance hängt von Implementierung und Arbeitslast ab.
F3: Wie beginnen wir, in einer OOP-Codebasis Richtung FP zu gehen?
A3: Beginne damit, reine Funktionen für Kernlogik zu extrahieren, Schleifen durch deklarative Array-Methoden zu ersetzen und Tests für kleine, isolierte Einheiten zu schreiben. Inkremetelle Refaktorierung reduziert Risiken.
Weiterführende Lektüre und interne Ressourcen
- Clean coding and architecture guide: /guides/clean-coding-principles
- Case studies on performance improvements: /case-studies/fintech-performance
- Architecture patterns and hybrid designs: /resources/architecture
1.
Project Euclid, “Object-Oriented Programming, Functional Programming, and R,” https://projecteuclid.org/journals/statistical-science/volume-29/issue-2/Object-Oriented-Programming-Functional-Programming-and-R/10.1214/13-STS452.pdf
2.
Scalac.io, “Functional Programming vs OOP,” https://scalac.io/blog/functional-programming-vs-oop/
3.
Industry adoption trends and surveys discussed in community reports; see overviews at https://scalac.io/blog/functional-programming-vs-oop/ for aggregate figures.
4.
Dev.to case study and community reports on paradigm shifts: Ben’s article, “OOP vs Functional Programming,” https://dev.to/ben/oop-vs-functional-programming-5ej4
🙋🏻♂️
KI schreibt Code.Sie lassen ihn bestehen.
Im Zeitalter der KI-Beschleunigung ist Clean Code nicht nur gute Praxis — es ist der Unterschied zwischen Systemen, die skalieren, und Codebasen, die unter ihrem eigenen Gewicht zusammenbrechen.