Erkunden Sie die Geschichte der Coda Panic Software, warum sie scheiterte, und die Lehren für moderne Entwicklungsteams. Erfahren Sie mehr über heutige robuste Alternativen.
February 5, 2026 (2mo ago)
Was war Coda Panic Software und was kann sie uns lehren?
Erkunden Sie die Geschichte der Coda Panic Software, warum sie scheiterte, und die Lehren für moderne Entwicklungsteams. Erfahren Sie mehr über heutige robuste Alternativen.
← Back to blog
Was war Coda Panic Software und was kann sie uns lehren?
Erkunden Sie die Geschichte der Coda Panic Software, warum sie scheiterte, und welche Lehren sie modernen Entwicklungsteams bietet. Lernen Sie die heute verfügbaren, robusten Alternativen kennen.
Einleitung
Sie haben vielleicht den Ausdruck coda panic software gesehen und angenommen, er beziehe sich auf eine kommerzielle App. Tut er nicht. Der Begriff verweist auf das verteilte Dateisystem Coda, ein Forschungsprojekt der Carnegie Mellon University, das darauf abzielte, katastrophale Synchronisationsfehler bei offline Arbeit zu lösen. Seine Geschichte zeigt, wie technische Brillanz von Komplexität zunichtegemacht werden kann, und bietet noch heute praktische Lektionen für Teams, die resiliente Systeme bauen wollen.1
Entwirrung des Erbes von Coda Panic Software
Stellen Sie sich vor, es ist Anfang der 1990er und Sie bearbeiten eine gemeinsame Datei bei einem unzuverlässigen Netzwerk. Jede Wiederverbindung ist ein Glücksspiel: Bleibt die Datei intakt oder stürzt das System ab? Coda wurde entwickelt, um das Arbeiten im Offline-Modus nahtlos zu machen. Es entstand aus akademischer Forschung an der Carnegie Mellon und konzentrierte sich darauf, Synchronisationsfehler zu reduzieren, die Daten beschädigen oder Systemabstürze auslösen konnten.1
Coda brachte wichtige Ideen ein — optimistische Replikation, aggressives client-seitiges Caching und Server-Replikation — um Nutzern das lokale Arbeiten zu ermöglichen und Änderungen später abzugleichen. Diese Ideen waren einflussreich, aber die tiefe Integration in den Kernel und die operative Komplexität schufen eine hohe Eintrittsbarriere.
Die historische Coda-Projektseite ist eine nützliche Primärquelle, um die ursprünglichen Ziele und Designentscheidungen zu verstehen.1
Die Vision versus die Realität
Coda war technisch anspruchsvoll, aber Installation und Wartung erforderten oft invasive Kernel-Änderungen. Diese Komplexität erzeugte eine Form von technischem Schuldenstand: hervorragende akademische Ergebnisse, die für den allgemeinen Gebrauch nicht praktikabel waren. Ein technisch überlegenes System kann trotzdem scheitern, wenn es Einfachheit und Entwicklererfahrung ignoriert.
„Technische Brillanz bedeutet wenig, wenn das Tool nicht zugänglich ist."
Codas Geschichte ist ein mahnendes Beispiel: Die besten Lösungen balancieren Ehrgeiz mit Nutzbarkeit und betriebssicherer Handhabung.
Aufstieg und Fall einer brillanten Idee
Als Nachfolger des Andrew File System (AFS) geboren, zielte Coda darauf ab, Nutzern das Bearbeiten von Dateien offline zu ermöglichen und Änderungen später mit optimistischer Replikation und client-seitigem Caching abzugleichen. Auf dem Papier sprach es ein echtes Problem für mobile und getrennt arbeitende Nutzer an.
Das Problem lähmender Komplexität
Codas Achillesferse war die Komplexität. Es erforderte Kernel-Modifikationen und tiefes betriebliches Wissen zur Installation und Wartung, was es auf Forschungslabore beschränkte. Während die Welt sich zu einfacheren, leichter einzuführenden Tools bewegte, blieb Coda schwer zu betreiben und weiterzuentwickeln.
Im Laufe der Zeit setzten sich Industrielösungen durch, die Bedienbarkeit und Zuverlässigkeit priorisierten. Moderne Anwendungen betonen sauberen Code, Entwicklererfahrung und Tools, die das operationelle Risiko minimieren.
Inneres von Codas Architektur und ihre fatalen Schwächen
Codas verteilte Architektur nutzte Server-Replikation und aggressives Client-Caching, um hohe Verfügbarkeit und Offline-Zugriff zu bieten. Aber Konfliktauflösung und Kernel-Ebene-Interaktionen führten einen gefährlichen Single Point of Failure ein: ein irreparabler Konflikt während der Synchronisation konnte einen Kernel-Panic auslösen und das gesamte System abstürzen lassen.
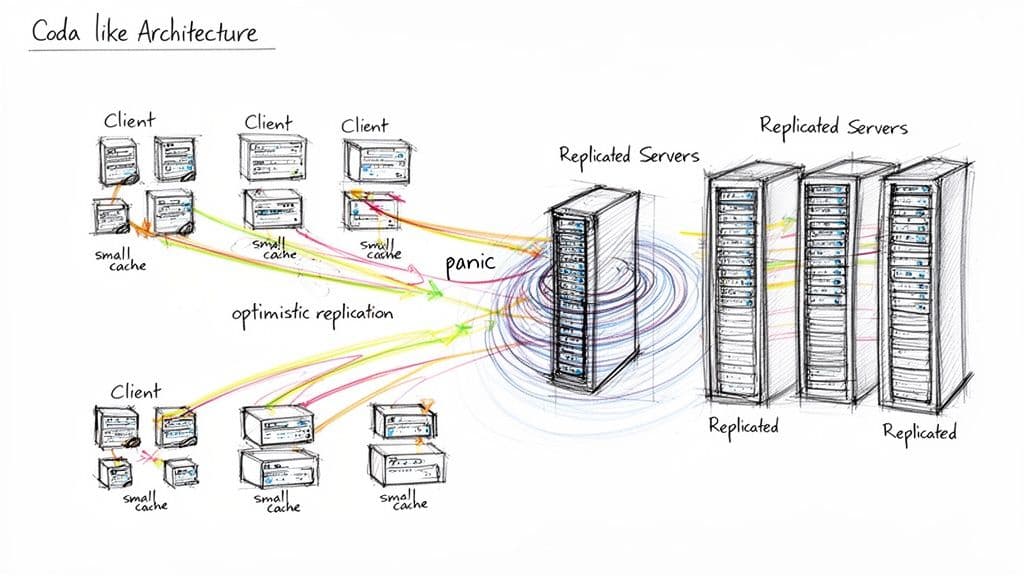
Die Anatomie eines Kernel-Panics
Offline zu arbeiten und dann zu synchronisieren sollte niemals das gesamte Betriebssystem gefährden. Codas Ansatz erlaubte es manchmal, dass Sync-Konflikte sichere Anwendungs-Level-Handling-Mechanismen umgingen und sich zu systemweiten Fehlern hochschaukelten. Diese Sprödigkeit unter realen Bedingungen untergrub seine Nützlichkeit.
Im Laufe der Zeit befassten sich verwandte Open-Source-Projekte mit vielen niedrigschwelligen Bugs, die verteilte Dateisysteme geplagt hatten, und zeigten, dass die zugrundeliegenden Probleme behoben werden konnten — vorausgesetzt, die Lösungen waren wartbar und fanden breite Akzeptanz.2
Codas architektonische Stärken vs. Schwächen
| Feature | Stärke (Vision) | Schwäche (Realität) |
|---|---|---|
| Optimistic replication | Ermöglicht Offline-Arbeit und priorisiert Produktivität | Unlösbare Konflikte konnten Schutzmechanismen umgehen und Systemausfälle verursachen |
| Client-side caching | Schneller lokaler Zugriff und Resilienz gegenüber Netzwerkproblemen | Beschädigte Caches und komplexe Wiederherstellungsprozesse riskierten Datenverlust |
| Server-side replication | Hohe Verfügbarkeit und Redundanz | Erhöhte Komplexität der Sync-Logik und mehr Konfliktszenarien |
| Kernel integration | Performance und transparentes Betriebssystemverhalten | Tiefe Integration bedeutete, dass Bugs das gesamte System zum Absturz bringen konnten |
Codas tiefe Betriebssystem-Integration war sowohl ein Performance-Vorteil als auch ein inakzeptables operationsrisiko für den Mainstream-Einsatz.
Moderne Echoes von Codas Fehlern
Die Kernlektion ist zeitlos: ein einzelner unbehandelter Fehlerpunkt kann ein gesamtes System unterminieren. Moderne Ingenieurpraktiken — Resilienzmuster, Eindämmung von Fehlern und saubere Architektur — sind direkte Reaktionen auf solche Risiken. Offene, gut gepflegte Plattformen und community-getriebene Fixes trugen dazu bei, das Auftreten der niedrigschwelligen Fehler zu reduzieren, die einst Projekte wie Coda versenkten.2
Werkzeugwahl in der Post-Coda-Ära
Die Coda-Geschichte lehrt Engineering-Leiter, Werkzeuge zu wählen, die Fähigkeit mit Entwicklererfahrung ausbalancieren. Heutige Editoren und IDEs liefern Workflows, die Codas ursprüngliches Versprechen einfangen — offline-freundlich, schnell und zuverlässig — ohne Operation am Kernel.
Für viele Teams ist der Editor oder die IDE ein täglicher Produktivitätsmultiplikator. Hier sind drei weit verbreitete Optionen:
Panic Nova: der Nachfolger des Coda-Editors
Panic Inc. (Hersteller von Nova) ist getrennt vom Coda-Dateisystem, obwohl Panics früherer Editor ebenfalls Coda hieß. Nova ist ein Mac-nativer Editor, bekannt für Geschwindigkeit, ein poliertes Interface und nahtlose Integration mit macOS. Er passt gut zu Teams, die auf Apple-Plattformen setzen und eine ablenkungsfreie Umgebung bevorzugen.4
Visual Studio Code: der Industriestandard
Visual Studio Code ist kostenlos, plattformübergreifend und wird von einem riesigen Ökosystem an Erweiterungen unterstützt. Es balanciert Benutzerfreundlichkeit mit Anpassbarkeit und integriert sich gut in moderne KI-Tools. Für viele Teams trifft es die richtige Mischung aus Flexibilität und Produktivität.5
JetBrains IDEs: die Power-Option
Produkte von JetBrains (IntelliJ, WebStorm usw.) bieten tiefe Code-Intelligenz, fortgeschrittenes Refactoring und starke Debugging-Tools. Sie sind ideal für große, komplexe Codebasen, in denen automatisierte Analysen und sicheres Refactoring besonders wichtig sind, können aber ressourcenintensiver sein.6
Moderner Editor-Vergleich für Clean-Code-Teams
| Feature | Panic Nova | Visual Studio Code | JetBrains (WebStorm/IntelliJ) |
|---|---|---|---|
| Performance & Feel | Native macOS-Geschwindigkeit und Reaktionsfähigkeit | Gute plattformübergreifende Performance; kann bei vielen Erweiterungen langsamer werden | Leistungsstark, kann ressourcenhungrig sein |
| AI pairing | Wachsende Erweiterungsunterstützung | Erstklassige KI-Tool-Integration | Starke eingebaute Code-Intelligenz |
| Refactoring & Analysis | Grundfunktionen out of the box; erweiterbar | Gute Werkzeuge und viele Erweiterungen | Branchenführendes automatisiertes Refactoring |
| Ecosystem | Kuratierte Erweiterungen | Riesiger Marktplatz | Robustess Plugin-Ökosystem |
Wählen Sie den Editor, der zur Plattform, zum Umfang und zu den Workflows Ihres Teams passt. Das richtige Tool befähigt Entwickler, anstatt Reibung zu erzeugen.
Wie Sie vermeiden, Ihre eigene Panic-Software zu bauen
Codas Erbe ist eine praktische Anleitung: Vermeiden Sie versteckte Fragilität, übermäßige Komplexität und ungehemmte technische Schulden. Konzentrieren Sie sich auf drei technische Säulen, um resiliente Systeme zu bauen:
Priorisieren Sie Einfachheit und Entwicklererfahrung
Wenn Onboarding Tage braucht oder neue Entwickler nicht in Stunden eine stabile Umgebung bekommen, hat Ihr System ein Reibungsproblem. Bevorzugen Sie klare APIs, minimalen operativen Overhead und schnelle Feedback-Schleifen für Entwickler.
Engineering für Resilienz
Designen Sie für Eindämmung. Fehler sollten isoliert, protokolliert und wiederherstellbar sein. Nutzen Sie klare Fehlergrenzen in Frontend-Frameworks sowie Circuit-Breaker, Retries und idempotente Operationen in Backend-Systemen.
Designen Sie für Evolution
Schreiben Sie modularen, gut dokumentierten Code unter Verwendung etablierter Muster. Machen Sie Änderungen sicher und kostengünstig, sodass die Codebasis sich ohne Angst weiterentwickeln kann.

Häufige Fragen zu Coda und moderner Entwicklung
Sind Panic Inc. (Hersteller von Nova) mit dem Coda-Dateisystem verbunden?
Nein. Panic Inc. ist eine eigenständige Firma, deren früherer Editor Coda hieß. Das CMU Coda verteilte Dateisystem ist ein unabhängiges Forschungsprojekt ohne direkte Verbindung zu Panics Produkten.4
Was ist die größte Lektion für einen CTO aus der Coda-Geschichte?
Die wichtigste Lektion ist, dass Entwicklererfahrung genauso wichtig ist wie technisches Design. Ein verlässliches, einfach zu nutzendes Werkzeug, das Teams verlässlich zum Deployen befähigt, ist einem technisch eleganten, aber riskanten System vorzuziehen.
Woran erkenne ich, ob meine Codebasis „Panic-Software“-Züge hat?
Achten Sie auf schmerzhaftes Onboarding, Dominoeffekt-Fehler, Angst vor Deployments und Teile des Codes, die niemand anzufassen wagt. Das sind Anzeichen dafür, dass ein objektives Audit und gezieltes Refactoring großen Nutzen bringen können.
Bei Clean Code Guy verwandeln wir fragile Codebasen in stabile, skalierbare Vermögenswerte. Unsere KI-bereiten Refactorings und Clean-Code-Audits helfen, „Panic-Software“-Züge zu entfernen, damit Teams mit Vertrauen ausliefern können.
Q&A — kurze Antworten auf häufige Anliegen
Q: Was sind sofortige Schritte, um Kaskadenfehler zu stoppen?
A: Fügen Sie klare Fehlergrenzen hinzu, erhöhen Sie die Observability und isolieren Sie Komponenten, damit Fehler sich nicht ausbreiten.
Q: Wie verbessere ich das Entwickler-Onboarding schnell?
A: Stellen Sie reproduzierbare Entwicklungsumgebungen, prägnante Setup-Skripte und einen Sandbox-Datensatz für frühe Validierung bereit.
Q: Wann sollte ich externe Hilfe hinzuziehen?
A: Wenn Deployments Angst auslösen oder kritische Bereiche faktisch Tabuzonen sind, kann ein Audit einen priorisierten Behebungsplan liefern.
1.
Carnegie Mellon University, „Coda Project,“ https://www.cs.cmu.edu/~coda/.
2.
OpenAFS project, ChangeLog for 1.4.15 documenting fixes related to volume read/write panics, https://www.openafs.org/frameset/dl/openafs/1.4.15/ChangeLog.
3.
Dropbox website, company information and product history, https://www.dropbox.com/.
4.
Panic Inc., Nova editor and company history, https://nova.app/.
5.
Visual Studio Code, product overview and downloads, https://code.visualstudio.com/.
6.
JetBrains, product pages for IntelliJ IDEA and WebStorm, https://www.jetbrains.com/.
🙋🏻♂️
KI schreibt Code.Sie lassen ihn bestehen.
Im Zeitalter der KI-Beschleunigung ist Clean Code nicht nur gute Praxis — es ist der Unterschied zwischen Systemen, die skalieren, und Codebasen, die unter ihrem eigenen Gewicht zusammenbrechen.