Explore functional programming vs OOP to understand which paradigm is best for your team. Discover how to build scalable and maintainable software.
November 27, 2025 (3mo ago)
Functional Programming vs OOP a Modern Comparison
Explore functional programming vs OOP to understand which paradigm is best for your team. Discover how to build scalable and maintainable software.
← Back to blog
Functional Programming vs OOP: A Modern Comparison
Summary: Compare functional programming and OOP to pick the right paradigm for scalability, maintainability, and team productivity.
Introduction
Choosing between functional programming (FP) and object-oriented programming (OOP) shapes how your team designs, tests, and maintains software. This guide lays out the core differences, practical trade-offs, and a hybrid approach so you can pick the right tools for your project and team.
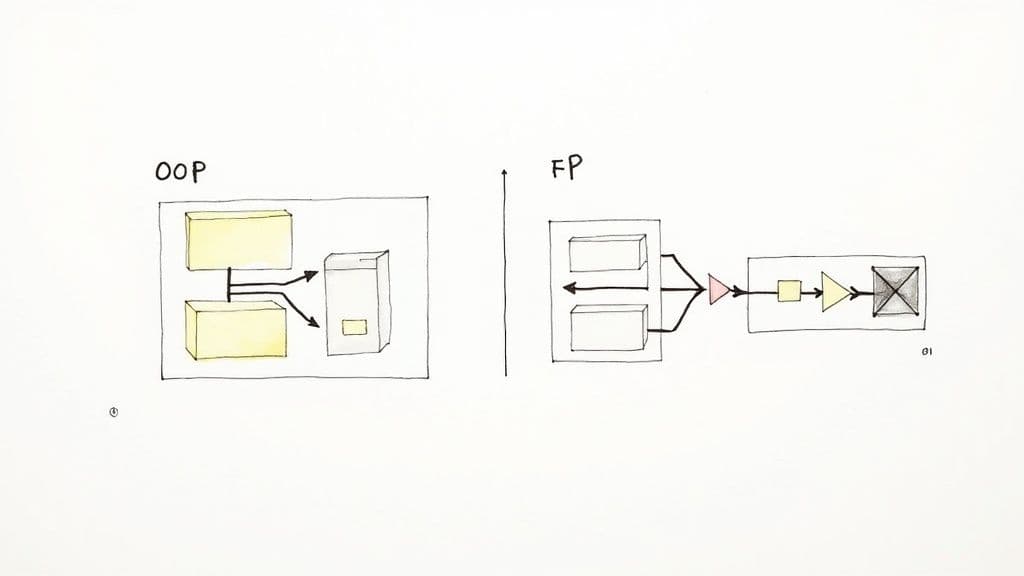
Deciding Between Functional Programming and OOP
The paradigm you choose affects architecture, developer experience, testing, and long-term maintenance. In many modern codebases, a hybrid approach—using OOP for high-level structure and FP for data transformations—offers the best of both worlds.
- OOP works well when systems are modelled as entities that own state and behavior, such as enterprise applications and complex GUIs.
- FP excels for data pipelines, concurrent systems, and anywhere predictable, side-effect-free code is critical.
Quick Reference: Which Paradigm to Start With
| Scenario | Recommended Paradigm | Why It Fits |
|---|---|---|
| Complex GUI with many interactive stateful components | OOP | Encapsulation makes each component responsible for its own state. |
| Large-scale enterprise system with a complex domain | OOP | Natural for modelling business entities and relationships. |
| Data processing pipeline or ETL | FP | Immutability and pure functions make flows predictable and parallelizable. |
| Real-time concurrent systems (e.g., chat server) | FP | Avoiding shared mutable state reduces race conditions. |
| Projects that need a single source of truth (e.g., state trees) | FP | Immutable state trees simplify reproducibility and debugging. |
| Teams experienced with class-based languages | OOP | Lower learning curve and faster initial productivity. |
Keep in mind these are starting points, not rigid rules. Many teams structure systems with OOP at the boundaries and FP for internal logic.
Deconstructing the Core Principles of OOP and FP
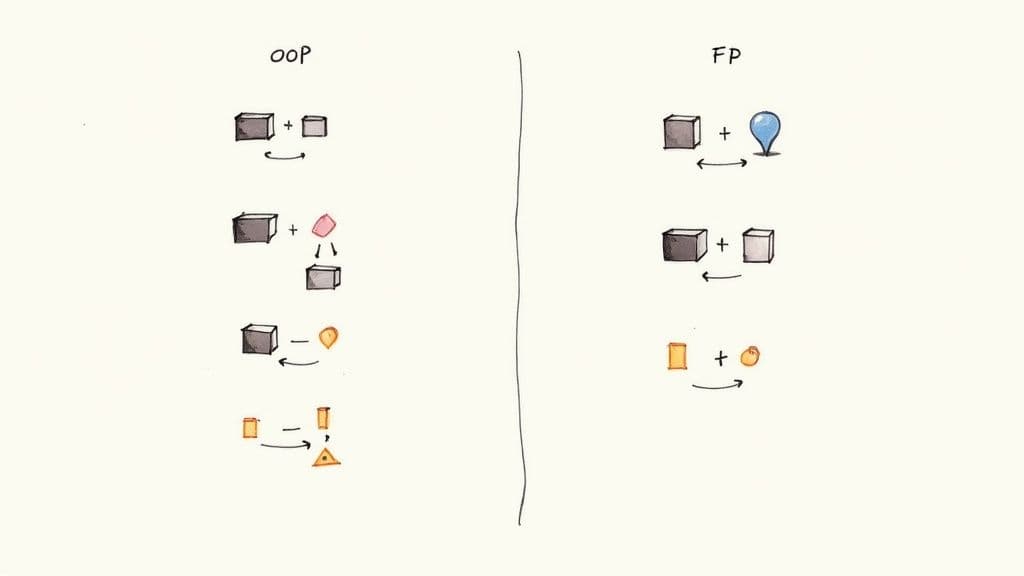
Object-oriented design bundles data and behavior in objects, using encapsulation, inheritance, and polymorphism to manage complexity. This approach remains dominant in many education programs and enterprise codebases1.
Functional programming emphasizes pure functions, immutability, and minimizing side effects. This yields highly testable, predictable code—valuable in systems where correctness and reproducibility matter most.
Practical Comparison: How They Manage State and Data
At the heart of the difference is how each paradigm handles change:
- OOP encapsulates mutable state inside objects and updates it via methods. That mirrors real-world modelling but can complicate concurrency and testing.
- FP treats data as immutable and transforms it via pure functions, creating new values instead of mutating existing ones. This pipeline approach simplifies reasoning and parallelism.
Adoption is shifting: while OOP remains common in many projects, FP usage has been growing, especially in data-rich domains23.
Side-by-Side Summary
| Concept | OOP | FP |
|---|---|---|
| Primary Unit | Objects that bundle state and behavior | Pure functions and immutable data |
| State | Mutable and encapsulated | Immutable; transformations produce new data |
| Data Flow | Objects call methods and change internal state | Data flows through function pipelines |
| Concurrency | Requires synchronization for shared state | Easier due to immutability and no shared state |
| Core Goal | Model real-world entities and interactions | Describe data transformations declaratively |
When to Use OOP vs FP
Choose OOP when your domain benefits from entity models that hold state and behavior. Choose FP for predictable transformations, concurrent processing, and testable pipelines. Many teams combine both: using classes for high-level architecture and pure functions for core logic.
For example, several fintech teams reported measurable gains after adopting FP for data processing—reductions in memory usage and faster batch processing in production workloads4.
Adopting a Hybrid Approach
A pragmatic path is to introduce functional patterns incrementally:
- Replace imperative loops with declarative array methods like map, filter, and reduce.
- Extract core business logic into pure functions that are easy to test and reuse.
- Keep objects for high-level orchestration and domain models, and use FP for data-heavy transformations.
This hybrid approach improves maintainability without a risky full rewrite. For teams focused on developer practices, follow clean code guides and internal docs to standardize patterns across the codebase.
Common Questions (FAQ)
Q1: Do we have to choose only one paradigm?
A1: No. Many teams mix paradigms—OOP for architecture and FP for data and core logic—so you can balance familiarity and predictability.
Q2: Is FP always faster or more memory-efficient?
A2: Not necessarily. FP’s immutability can increase allocations, but thoughtful data-structure choices and runtime optimizations often mitigate overhead. Performance depends on implementation and workload.
Q3: How do we start moving toward FP in an OOP codebase?
A3: Begin by extracting pure functions for core logic, replacing loops with declarative array methods, and writing tests for small, isolated units. Incremental refactoring reduces risk.
Further Reading and Internal Resources
- Clean coding and architecture guide: /guides/clean-coding-principles
- Case studies on performance improvements: /case-studies/fintech-performance
- Architecture patterns and hybrid designs: /resources/architecture
1.
Project Euclid, “Object-Oriented Programming, Functional Programming, and R,” https://projecteuclid.org/journals/statistical-science/volume-29/issue-2/Object-Oriented-Programming-Functional-Programming-and-R/10.1214/13-STS452.pdf
2.
Scalac.io, “Functional Programming vs OOP,” https://scalac.io/blog/functional-programming-vs-oop/
3.
Industry adoption trends and surveys discussed in community reports; see overviews at https://scalac.io/blog/functional-programming-vs-oop/ for aggregate figures.
4.
Dev.to case study and community reports on paradigm shifts: Ben’s article, “OOP vs Functional Programming,” https://dev.to/ben/oop-vs-functional-programming-5ej4
🙋🏻♂️
AI writes code.You make it last.
In the age of AI acceleration, clean code isn’t just good practice — it’s the difference between systems that scale and codebases that collapse under their own weight.